
Maintaining a service that processes over a billion events per day poses many learning opportunities. In an ecommerce landscape, our service needs to be ready to handle global traffic, flash sales, holiday seasons, failovers and the like. Within this blog, I'll detail how I scaled our Server Pixels service to increase its event processing performance by 170%, from 7.75 thousand events per second per pod to 21 thousand events per second per pod.
But First, What is a Server Pixel?
Capturing a Shopify customer’s journey is critical to contributing insights into marketing efforts of Shopify merchants. Similar to Web Pixels, Server Pixels grants Shopify merchants the freedom to activate and understand their customers’ behavioral data by sending this structured data from storefronts to marketing partners. However, unlike the Web Pixel service, Server Pixels sends these events through the server rather than client-side. This server-side data sharing is proven to be more reliable allowing for better control and observability of outgoing data to our partners’ servers. The merchant benefits from this as they are able to drive more sales at a lower cost of acquisition (CAC). With regional opt-out privacy regulations built into our service, only customers who have allowed tracking will have their events processed and sent to partners. Key events in a customer’s journey on a storefront are captured such as checkout completion, search submissions and product views. Server Pixels is a service written in Golang which validates, processes, augments, and consequently, produces more than one billion customer events per day. However, with the management of such a large number of events, problems of scale start to emerge.
The Problem
Server Pixels leverages Kafka infrastructure to manage the consumption and production of events. We began to have a problem with our scale when an increase in customer events triggered an increase in consumption lag for our Kafka’s input topic. Our service was susceptible to falling behind events if any downstream components slowed down. Shown in the diagram below, our downstream components process (parse, validate, and augment) and produce events in batches:
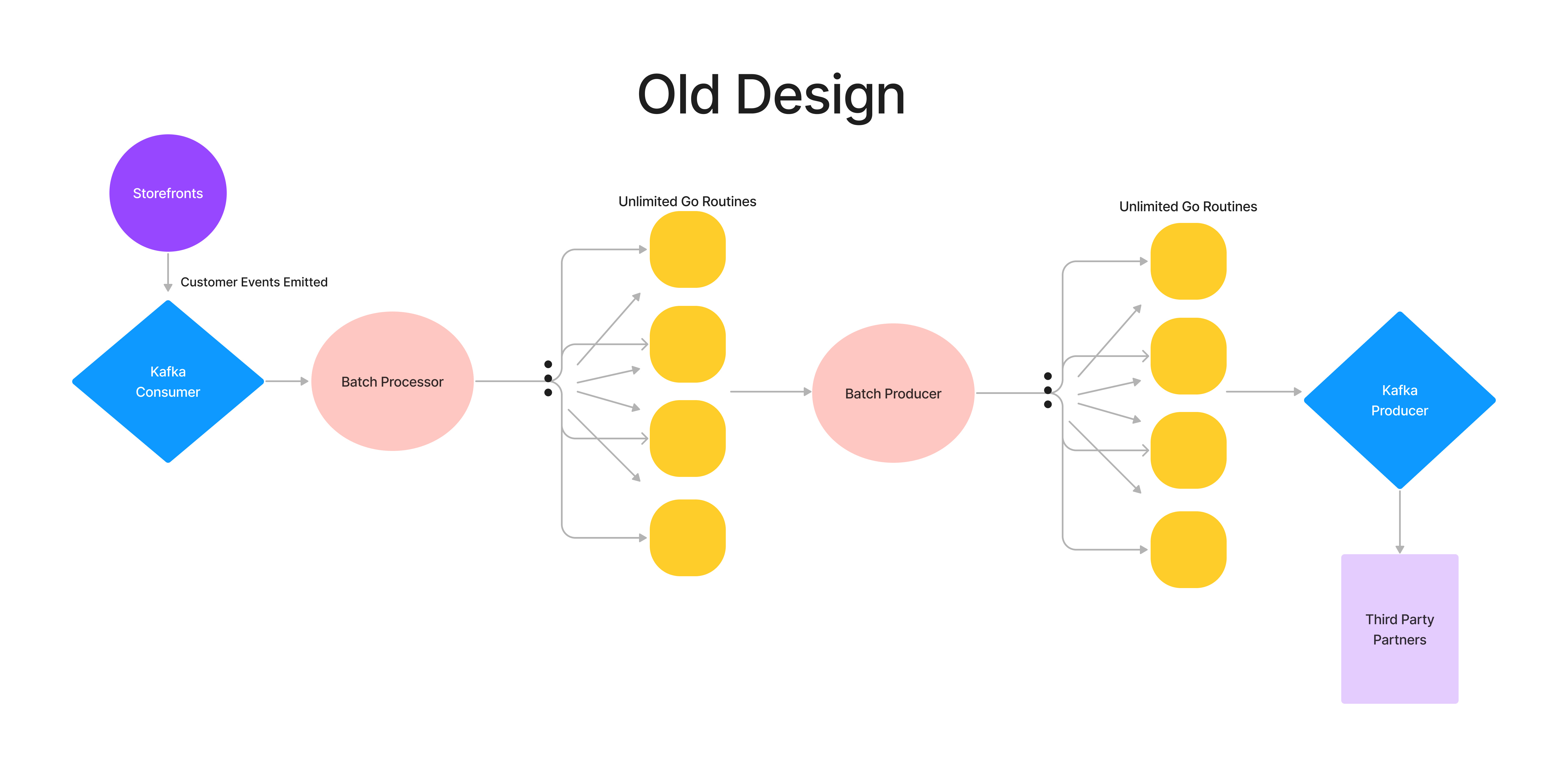
The problem with our original design was that an unlimited number of threads would get spawned when batch events needed to be processed or produced. So when our service received an increase in events, an unsustainable number of goroutines were generated and ran concurrently.
Goroutines can be thought of as lightweight threads that are functions or methods that run concurrently with other functions and threads. In a service, spawning an unlimited number of goroutines to execute increasingly growing tasks on a queue is never ideal. The machine executing these tasks will continue to expend its resources, like CPU and memory, until it reaches its limit. Furthermore, our team has a service level objective (SLO) of five minutes for event processing, so any delays in processing our data would exceed our processing beyond its timed deadline. In anticipation of three times the usual load for BFCM, we needed a way for our service to work smarter, not harder.
Our solution? Go worker pools.
The Solution
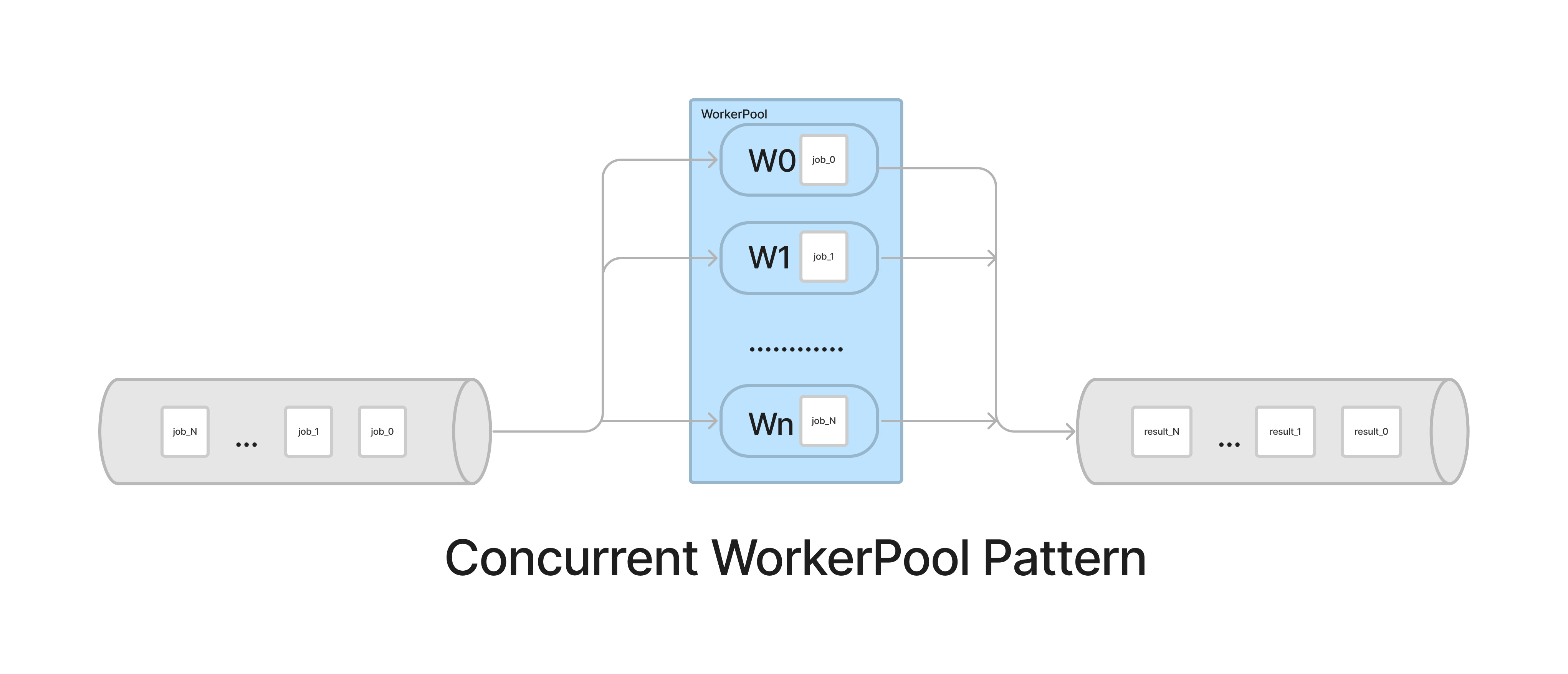
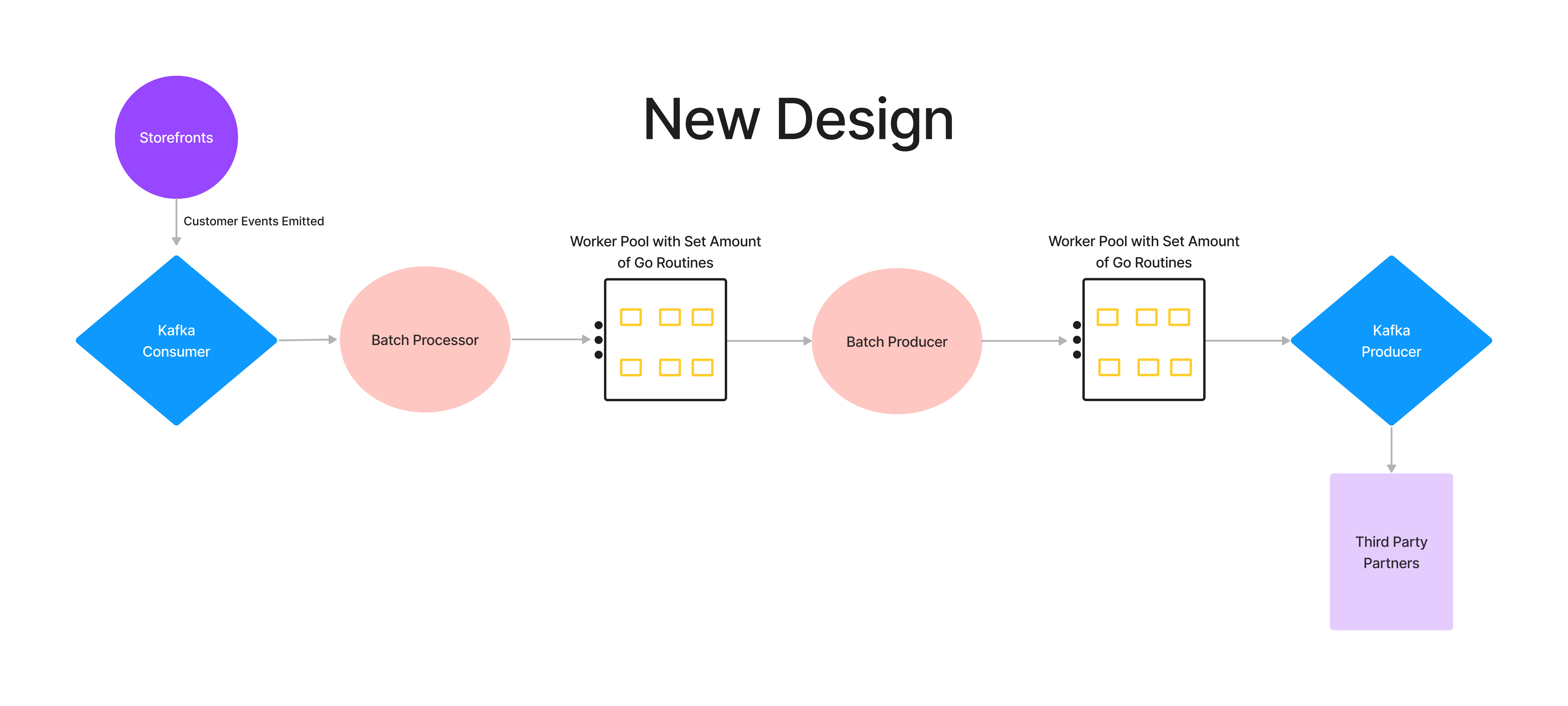
The worker pool pattern is a design in which a fixed number of workers are given a stream of tasks to process in a queue. The tasks stay in the queue until a worker is free to pick up the task and execute it. Worker pools are great for controlling the concurrent execution for a set of defined jobs. As a result of these workers controlling the amount of concurrent goroutines in action, less stress is put on our system’s resources. This design also worked perfectly for scaling up in anticipation of BFCM without relying entirely on vertical or horizontal scaling.
When tasked with this new design, I was surprised at the intuitive setup for worker pools. The premise was creating a Go channel that receives a stream of jobs. You can think of Go channels as pipes that connect concurrent goroutines together, allowing them to communicate with each other. You send values into channels from one goroutine and receive those values into another goroutine. The Go workers retrieve their jobs from a channel as they become available, given the worker isn’t busy processing another job. Concurrently, the results of these jobs are sent to another Go channel or to another part of the pipeline.
So let me take you through the logistics of the code!
The Code
I defined a worker interface that requires a CompleteJobs function that requires a go channel of type Job.
The Job type takes the event batch, that’s integral to completing the task, as a parameter. Other types, like NewProcessorJob, can inherit from this struct to fit different use cases of the specific task.
New workers are created using the function NewWorker. It takes workFunc as a parameter which processes the jobs. This workFunc can be tailored to any use case, so we can use the same Worker interface for different components to do different types of work. The core of what makes this design powerful is that the Worker interface is used amongst different components to do varying different types of tasks based on the Job spec.
CompleteJobs will call workFunc on each Job as it receives it from the jobs channel.
Now let’s tie it all together.
Above is an example of how I used workers to process our events in our pipeline. A job channel and a set number of numWorkers workers are initialized. The workers are then posed to receive from the jobs channel in the CompleteJobs function in a goroutine. Putting go before the CompleteJobs function allows the function to run in a goroutine!
As event batches get consumed in the for loop above, the batch is converted into a Job that’s emitted to the jobs channel with the go worker.CompleteJobs(jobs, &producerWg) runs concurrently and receives these jobs.
But wait, how do the workers know when to stop processing events?
When the system is ready to be scaled down, wait groups are used to ensure that any existing tasks in flight are completed before the system shuts down. A waitGroup is a type of counter in Go that blocks the execution of a function until its internal counter becomes zero. As the workers were created above, the waitGroup counter was incremented for every worker that was created with the function producerWg.Add(1). In the CompleteJobs function wg.Done() is executed when the jobs channel is closed and jobs stop being received. wg.Done decrements the waitGroup counter for every worker.
When a context cancel signal is received (signified by <- ctx.Done() above ), the remaining batches are sent to the Job channel so the workers can finish their execution. The Job channel is closed safely enabling the workers to break out of the loop in CompleteJobs and stop processing jobs. At this point, the WaitGroups’ counters are zero and the outputBatches channel,where the results of the jobs get sent to, can be closed safely.
The Improvements
Once deployed, the time improvement using the new worker pool design was promising. I conducted load testing that showed as more workers were added, more events could be processed on one pod. As mentioned before, in our previous implementation our service could only handle around 7.75 thousand events per second per pod in production without adding to our consumption lag.
My team initially set the number of workers to 15 each in the processor and producer. This introduced a processing lift of 66% (12.9 thousand events per second per pod). By upping the workers to 50, we increased our event load by 149% from the old design resulting in 19.3 thousand events per second per pod. Currently, with performance improvements we can do 21 thousand events per second per pod. A 170% increase! This was a great win for the team and gave us the foundation to be adequately prepared for BFCM 2021, where we experienced a max of 46 thousand events per second!
Go worker pools are a lightweight solution to speed up computation and allow concurrent tasks to be more performant. This go worker pool design has been reused to work with other components of our service such as validation, parsing, and augmentation.
By using the same Worker interface for different components, we can scale out each part of our pipeline differently to meet its use case and expected load.
Cheers to more quiet BFCMs!
Kyra Stephen is a backend software developer on the Event Streaming - Customer Behavior team at Shopify. She is passionate about working on technology that impacts users and makes their lives easier. She also loves playing tennis, obsessing about music and being in the sun as much as possible.
Wherever you are, your next journey starts here! If building systems from the ground up to solve real-world problems interests you, our Engineering blog has stories about other challenges we have encountered. Intrigued? Visit our Engineering career page to find out about our open positions and learn about Digital by Design.