


GitHub personal access tokens (PATs) are like a key: a very, very large key that opens a very, very wide door. Long-lived tokens that have all the access of a developer’s account won’t just cause a leak—it’ll be a flood. GitHub’s built-in token is useful, but has limitations of its own: it can’t access repo-external resources and it won’t trigger downstream actions (by design). Given the limitations with these two blessed authentication paths, what do you do when these methods don’t work for your use case? We encountered this problem in some of our workflows, and solved it by building a system to rotate tokens automatically. Here’s how we did it, and how you can use it too.
The Problem
At Shopify’s scale, we have an awkward relationship with GitHub’s authentication methods. We have various use cases for our automated workflows (performed largely via GitHub Actions) that preclude the use of GitHub’s automatic token authentication (appropriately named GITHUB_TOKEN). These include:
- Cloning actions or code from another private repository
- Pushing issues or pull requests into organization-level projects
- Triggering workflows that need to trigger other downstream workflows (that don’t use the
repository_dispatchorworkflow_dispatchtriggers)
A quick internet search proves fruitful: use PATs! PATs can be scoped to allow for wide access to resources at the organization level, allow workflows to trigger other workflows, and allow repositories to clone each other as needed. Even better, they can be configured to never expire, so developers can basically fire-and-forget. Perfect, right?
Well…
- PATs are vulnerable to developer churn. If a developer leaves Shopify and their tokens lose access to Shopify resources, suddenly workflows break in a non-obvious way which can cost developers valuable time and operational headaches.
- PATs attribute actions taken to the user account associated with them. My GitHub stats would love to report that user “Evan Lee” is creating and assigning issues as soon as they enter the backlog, but my security teams or troubleshooting developers might not enjoy the difficulty to troubleshoot that, actually, there’s a workflow named “assign_and_triage_issues” that is doing the heavy lifting.
- Lastly, PATs do not have rotation or expiry requirements that can be enforced at the organization level. I certainly don’t want to be manually recreating PATs every 30 or 90 days and then manually updating the repository secrets.
The Solution
As a tools engineer, I want my developers’ lives to be easier than before while subscribing to security considerations. Designing any system to fill this problem space would have to be guided by the following principles:
- Transparent, automatic rotations
- Short-lived expirations
- Break-glass manual interventions
- Visible and auditable logged activities
- Approval & onboarding flow
- Resiliency to developer churn

This particular serverless architecture was chosen over other, service-full designs due to its simplicity in delegating a lot of work onto GitHub products to reduce long-term maintenance burden on our team. Out of the box, GitHub provides:
- Simple, flexible scheduling options that operate in a black box
- Managed infrastructure
- Change management and approval process via the pull request process in combination with the code owners feature and branch protections
- Simple, secure secrets management
- Historical tracking/auditing of actions taken and/or changed
- Manual break-glass UI for emergency scenarios
These are capabilities our service can leverage so that the development maintenance burden of our team shrinks to things like maintaining a list of YAML files, some Typescript Action code, and operational monitoring.
Our solution also makes use of a GitHub App to generate secrets, instead of associating secrets to personal developer accounts. As GitHub Apps are first-class actors in GitHub’s domain, with their own separate credentials, secrets, and names, we were able to increase the resiliency of many of our automations against things like developer churn and actor misattribution.
Lastly, our solution reduces developer friction as much as possible by replicating the usage patterns of PATs while transparently rotating them in the background. By placing the generated secrets in the repository secrets, developers are able to reference and use them in the exact same way as PATs were previously being used. This allowed us to smoothly migrate many existing workflows without downtime or maintenance required.
The Gotchas
The best laid plans often go awry. Throughout the prototyping and implementation process, there were a few bumps in the road that led to iterations in the design. Here are a few of the key gotchas that we encountered.
Cost
Shopify makes use of GitHub’s Larger Action Runners plan to run workloads, which (of course) we as an organization need to pay for.
Our original cost estimates included certain calculation assumptions and misconceptions that ended up not holding true in production.
The first assumption was mostly due to a lack of research: the granularity of what GitHub refers to as “billable minutes”. Understanding that the granularity of a billable minute is at, well, the minute-level was one thing; the other thing was the way that the rounding and bucketing works.
Billable minute calculations are not performed at an organization level, but rather at the job level. Each workflow has N underlying jobs, and each underlying job has an execution duration that is rounded to the nearest minute. These rounded nearest minutes are then summed together–even if the jobs were run in parallel–and billed to the organization. Because of this, workflows that ran 10 parallel jobs that would execute in 1 second each would end up accruing 10 billable minutes.
These miscalculations ended up exploding our costs during our prototyping phase and led to an architecture refactoring to sequentially executing all downstream workflows in a single job.
💡 A great resource here is GitHub’s Pricing Calculator for Actions, which should present a much clearer picture of estimated costs for your workloads.
Scheduling
Installation tokens for GitHub Apps expire after one hour. Initially, we were intending on running token rotations using the schedule trigger for workflows, and running each workflow every 45 minutes to compensate for any lag or timing overhead that might cause execution or scheduling delays.
However, during the prototyping phase when the scale of customer rotations was less than 10, we uncovered a major sharp edge in the way that the GitHub schedule trigger actually works:
schedule event allows you to trigger a workflow at a scheduled time. You can schedule a workflow to run at specific UTC times using POSIX cron syntax. Scheduled workflows run on the latest commit on the default or base branch. The shortest interval you can run scheduled workflows is once every 5 minutes.
Initially, we made use of the schedule trigger with the value */45 * * * * in order to trigger workflow runs every 45 minutes. However, we found that this trigger was extremely unreliable, sometimes not actually triggering a run for up to tens of minutes. After investigation, we found that the schedule trigger was considered best-effort and was heavily dependent on the load of the GitHub Actions service at any given time (Upptime.js has a great post about this particular facet of GitHub Actions). Instead, we decided to move to an explicit declaration of minutes-on-the-hour schedule instead of the every-X-minutes'' scheme to increase the reliability of scheduling. In addition, we reduced the frequency of runs from 45 minutes to every 15 minutes so that the workflow runs 4 times every hour.
Our workflows now look like this:
Ergonomics
The service onboarding process evolved many times over the course of design and implementation.
The initial iteration of the onboarding process involved reading through a README, copying a file, reading through the comments in that file, and replacing certain REPLACE_ME_X fields with the actual values that the user needed to specify. To increase confidence in this process, we even set up a step in our CI pipeline to lint the created files and ensure that all REPLACE_ME_X fields were replaced with actual values.
However, during user trials, this process ended up being extremely reliant on the developer’s level of comfort and experience with specific domain knowledge (in this case, requiring at least a base knowledge of GitHub Actions and how they worked). Those with less experience with GitHub Actions reported the process to be confusing, opaque, and unclear, no matter how many entries were added to the FAQ.
Our next version of the onboarding process instead walked the user through a very simple wizard which naively rendered a template with the raw inputs that the user gave to a list of prompted questions. This reduced the number of missing field errors when onboarding, but did not decrease the level of domain knowledge required.
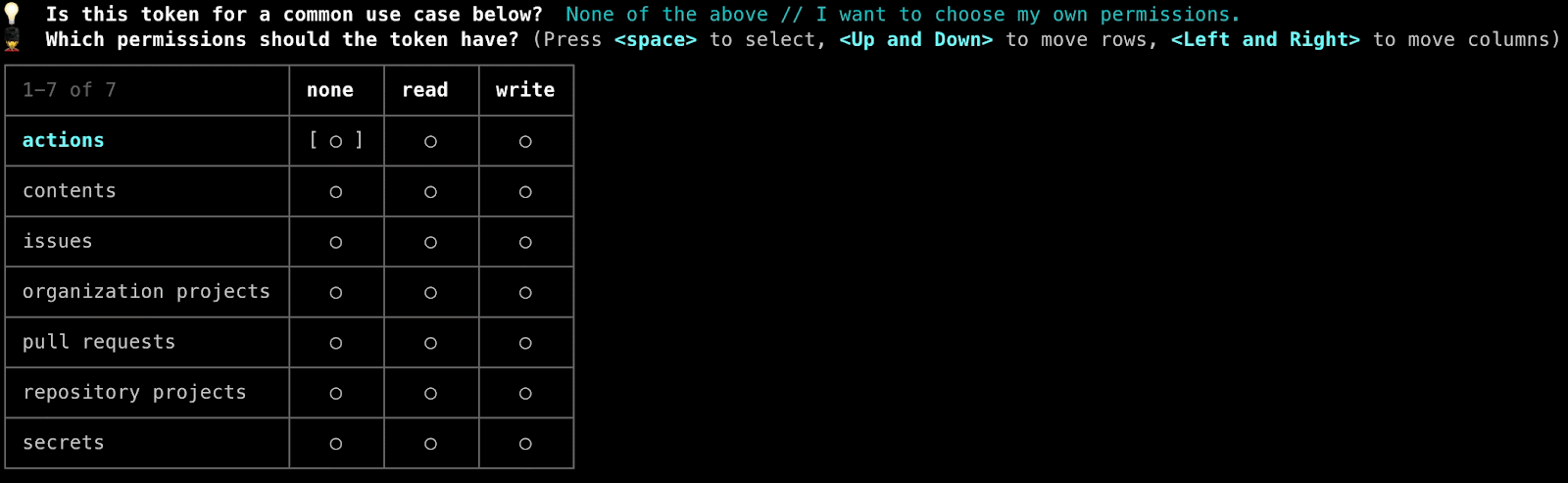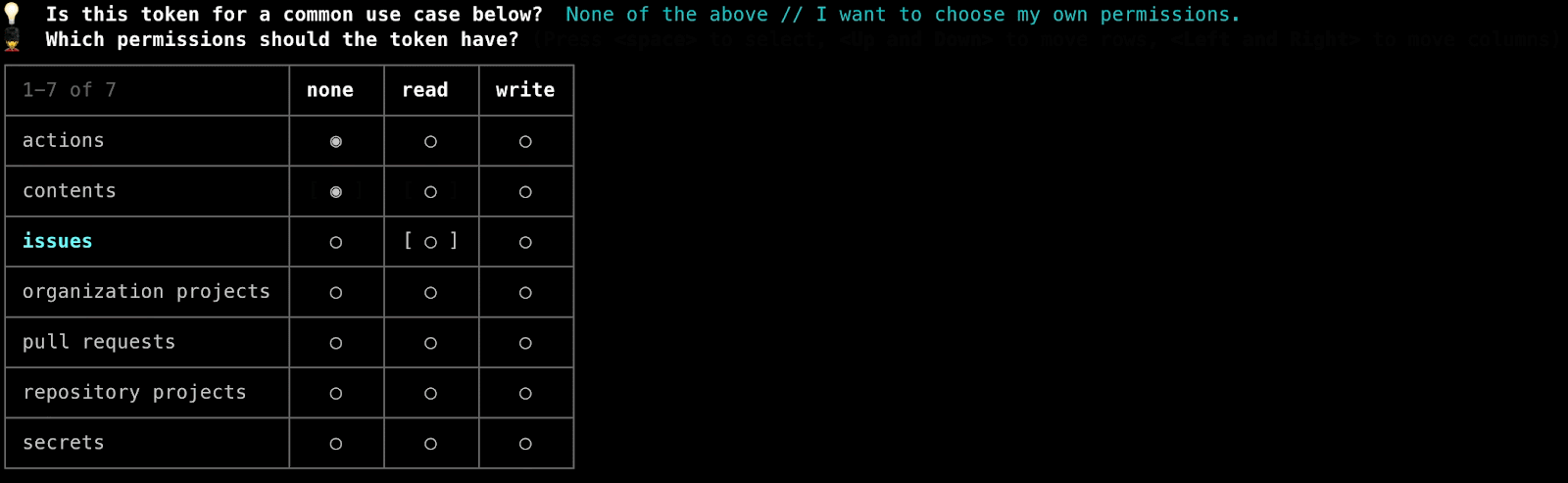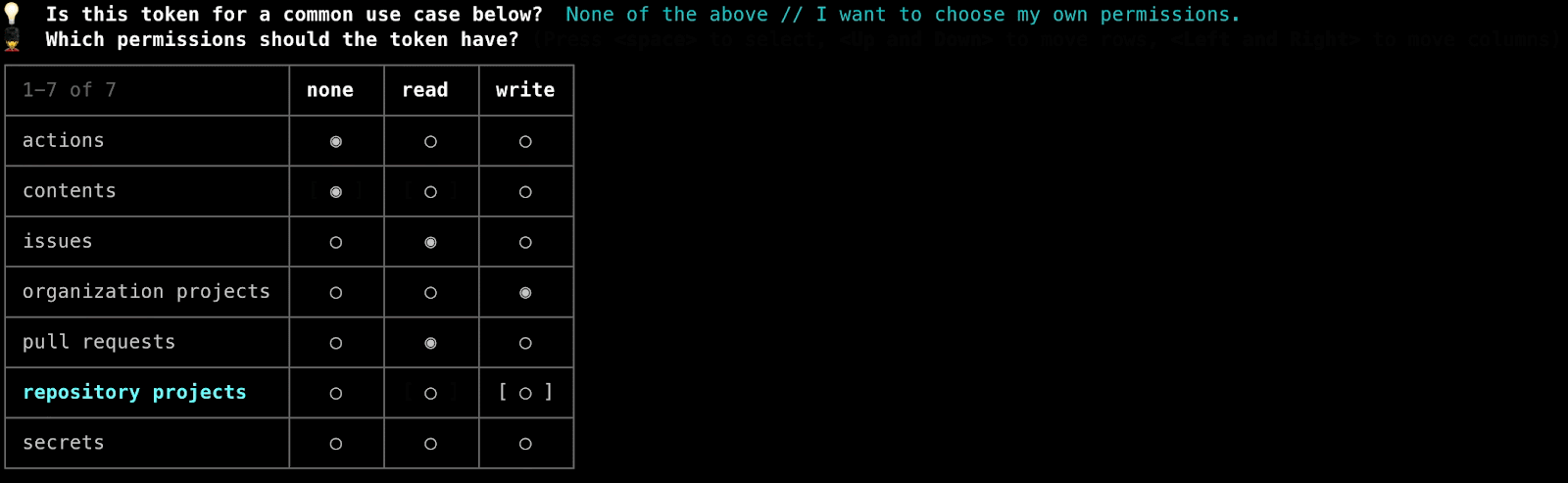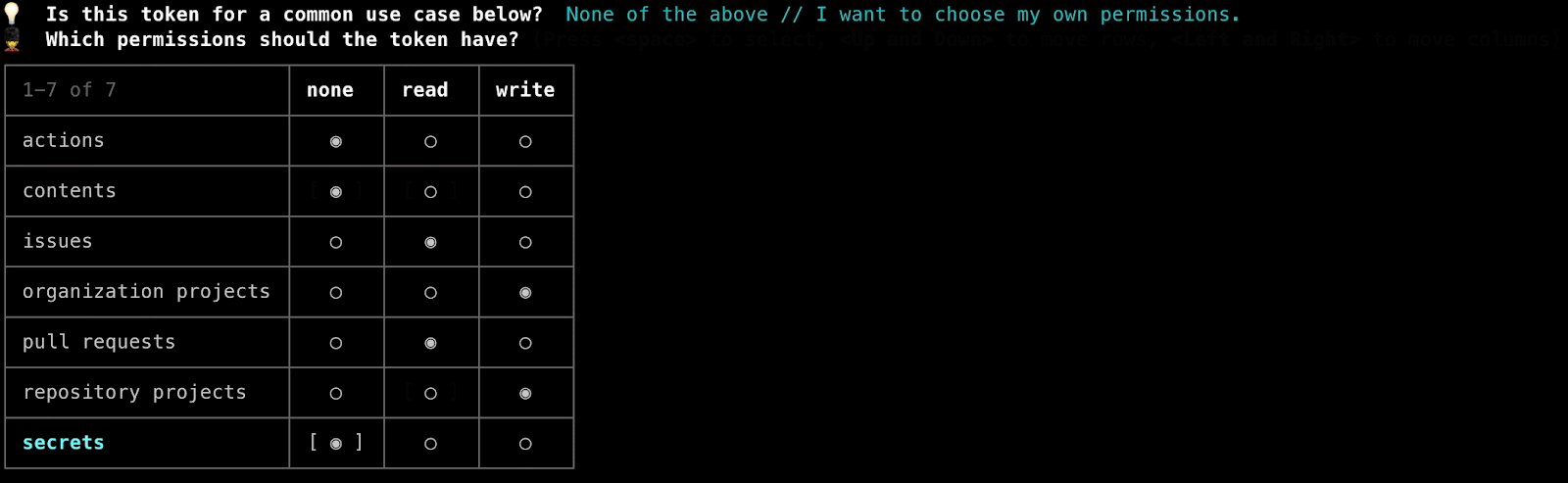
The largest pain point that users reported was not knowing which permissions to grant to a token in order fulfill their particular use case. In addition, since this field needed to be formatted as a JSON blob in order to be properly deserialized by the action, users reported that crafting this blob was both annoying and slightly more time consuming than expected.
The final iteration of this process seen below (and currently used in production) is much more focused on human friendliness, offering a choice from a list of very common use case descriptions (that would then be translated to the appropriate permissions blob) but also allowing power users to designate their own permissions. The permissions input was also reworked into a graphical matrix representation instead of requiring the user to provide a raw input.
You Can Do It Too!
So, you’ve just finished your tenth readthrough of this article and want to implement a tokens rotation system of your own.
At a high level, these are the steps that we went through when creating this system:
1. Create a centralized GitHub App for your organization with a meaningful name. This name will show up as the actor in things like Issue Timelines, so make sure the name is at least somewhat meaningful.
2. Give your new App the superset of all expected permissions. Apps can only give their tokens a subset of their own permissions, so try to determine the largest possible scope to fill all downstream use cases. This is configurable at any time by an organization admin, so no need to get this perfect the first time (we had to adjust permissions 4-5 times!)
3. Install the App on the organization, giving it access to All Repositories.
4. Create a centralized repository that will host all the rotation workflows and the rotation job action code.
5. Place the App’s secrets into the repository Secrets. This includes items like the private key, the client secret, etc.
6. Write a custom action in the repository that will handle a single token rotation. Our version is written in Typescript (compiled down to Javascript for the Action runtime) and is unfortunately closed-source.
The Action accepts the following parameters:
- Private key
- Application ID
- Client ID
- Client Secret
- App Installation ID
- Repository Organization (ours defaults to “Shopify”)
- Repository Name (the location of the token)
- Accessible Repositories (the repos the token has access to)
- Permissions (a JSON blob of permission to level of access)
- Target Secret Name (the name of the token as will be placed in the target repository)
The Action takes the following steps:
7. Optional: Create an onboarding flow. At Shopify, we prefer a self-service registry system that customer teams can use to onboard themselves to the system. If your organization prefers to have an operations team maintain the system (including managing token rotations), then you might not need an onboarding flow.
Our onboarding flow uses plop.js to walk users through selecting the appropriate permissions, naming the secrets, and designating which repository the secret should live in. The onboarding process then uses the inputs to render a GitHub Actions workflow definition file and generates a PR on the repository, which then gets approved and merged in at a later time.
Customer workflows now look like this example:
8. Optional: Write a test or canary workflow to ensure that your action code works properly. At Shopify, we have a canary workflow that we monitor metrics on to ensure uptime of the system.
9. Write a centralized action and workflow that will run all the other workflows in sequence.
Here’s an example of what our consolidated workflow looks like:
10. Optional: Publish operational metrics for visibility into service performance. Our KPIs include:
- GitHub primary rate limit exhaustion and availability
- Canary uptime percentage
- Secret rotation error rates
There you have it. We created a solution to fix a problem that lives in the gap between two tried-and-true solutions: personal access tokens and built-in authentication. Driven by our use cases that need to (a) trigger downstream actions and (b) access repo-external resources that preclude the use of the built-in authentication method, we also wanted to build a solution that was (c) resilient to developer churn and (d) shrink the blast radius for leaked secrets. All of this led us to engineering our solution to automatically rotate GitHub tokens: so you don’t have to.
Evan Lee is a Senior Developer on Shopify’s Developer Infrastructure team. You can connect with him on Twitter or GitHub.
We all get shit done, ship fast, and learn. We operate on low process and high trust, and trade on impact. You have to care deeply about what you’re doing, and commit to continuously developing your craft, to keep pace here. If you’re seeking hypergrowth, can solve complex problems, and can thrive on change (and a bit of chaos), you’ve found the right place. Visit our Engineering career page to find your role.