


We recently announced Flex Comp, our new approach to compensation that puts product thinking at the forefront of how Shopify employees (a.k.a Shopifolk) get paid. Flex Comp gives Shopify employees the ability to choose how they want to allocate their total reward between base salary, Restricted Stock Units (RSUs), and Stock Options today, with new features like Shop Cash in the future. We’ve removed one-year cliffs on equity, and because life changes all the time, we allow employees to change their allocations a few times a year during allocation windows. All of this is handled through a clean user interface that’s simple to use and makes it crystal clear how much an employee earns with the allocation they’ve selected.
For employees onboarding into the new comp system, adjusting their total rewards allocation by dragging a slider to the right or left is incredibly simple; but for development teams to actually build this one-of-a-kind system, it’s been anything but.
Naturally, when it comes to compensation, we can’t share every detail of the project. That said, this project taught us many lessons and inspired creative solutions that we think anyone setting out to build something innovative can benefit from. In this post, we’ll share some of the technical challenges we solved along the way to take Flex Comp from a blue-sky idea of what compensation could be, to a real system used by Shopifolk all over the world today.
By Shopifolk, For Shopifolk
We had a strong vision for what this system could be and we were ready to devote the necessary resources to make it happen. As big believers in product thinking, we saw this build as the perfect opportunity to turn this philosophy inwards. We also committed to building it as fast as we could—not only because of things like pay periods and allocation windows that all needed to be timed correctly with the launch—but because we wanted to. Parkinson’s Law dictates that “work expands so as to fill the time available for its completion.” A project like this, building something we’d never built before, could take years if we let it. That’s just not how we do things around here.
Establishing a detailed and clearly prioritized backlog of isolated deliverables was an important first step. We assembled teams of front and back end developers, making sure that specific knowledge and skill sets (for example, a deep understanding of specific elements of our infrastructure, how code is indexed/searched through internal tools) were put to good use.
We established API contracts between the front end and back end throughout the project, with the earliest contract defined within the first week. As more requirements were solidified, we made sure to add to the API contract before making any back end changes, so the front end could continue to be built independently and remain agnostic to the many back end changes taking place early in the build.
Implementing Privacy Controls in Shopify's Codebase
Since this project involved building a tool that would allow employees to customize their compensation, we wanted to ensure that we placed appropriate privacy controls on the project. For example, we chose to build Flex Comp in a private repository only accessible to those on the dedicated project team. As another example, we also implemented controls through how we approached event encryption.
The Matter of Github Permissions
To ensure that the Flex Comp project's Github repository would only be accessible by a small group working on the project, we created a new Github organization solely for the Flex Comp project so that we could begin building the tool. The Flex Comp repository was then integrated into the Shopify organization to leverage the internal tooling that makes deploying our infrastructure seamless.
Shopify's Github is set up so that when users join the Shopify Github organization, they’re automatically added to the Shopifolk Github team, which allows access to many Shopify repos. To access the Flex Comp project, users need to be added to a specific Github team reserved for the core contributors of the Flex Comp project. This allows us to control Github permissioning with more granularity and to enforce tighter access control rules while continuing to use the Shopify Github organization and reaping the benefits of using internal tools connected to the organization.
How a Message in a Bottle Inspired Us to Rethink Eventing
With the introduction of data from the Flex Comp project into our data pipeline, we began exploring ways to further protect event payloads so we could perform product analytics and enable future studies on allocation behaviors. In addition to the existing Kafka platform, we looked at many alternative solutions and even considered provisioning an entirely new analytics platform instance to separate this sensitive data. Due to time constraints this wasn’t feasible and we needed something that the data team could access quickly, easily, and securely.
True story: one evening a member of our dev team was out for a walk when he found a bottle on the street with a secret illegible message inside, and he thought “What if we just encrypt the entire payload before sending the Kafka event?” Eureka. We could utilize the existing internal eventing platform, with the additional step of encrypting the entire payload before sending the Kafka event. The data team was already set up to ingest data from the internal eventing platform and only needed to add a decryption layer for these topics to ingest the payloads allowing us to move quickly.
We discussed the trade-offs of using symmetric vs. asymmetric encryption and decided to go with asymmetric encryption. Symmetric encryption allows for quicker decryption, but anyone with the symmetric key can both encrypt and decrypt any of the payload information. Whereas with asymmetric encryption, the data team could share the public key with any team who wants to generate and send encrypted payloads, but only the data team could decrypt the payloads with the private key.
Our data team generated a 4096 bit RSA key pair and shared the public key with us to encrypt our event payloads. Now it became very simple to send events from our Ruby on Rails app to our Kafka topics as seen here:
All of our events could now use the internal eventing platform, and once the events reach the data warehouse the payload can be decrypted with the RSA private key and used for analytics/metrics as seen here:
As we started to create and send these encrypted events to various Kafka topics, we found that for certain events our structured payloads were too large for the 4096 bit RSA key. As a result, we generated a 6144 bit RSA key pair which was used for only the events with a larger payload. The reason we did not use the 6144 bit key pair for all events regardless of payload size is because of the performance impact. Being able to choose the correct encryption key size depending on the payload allowed us to optimize the performance impact of decrypting the payloads at the tail end once it reaches the data warehouse.
The 4096/6144 bit RSA key pair encryption approach worked, but we also learned from it. We learned that a better approach would have been to use both symmetric and asymmetric encryption together to solve the issue of encrypting large payloads.
At the application level (generating the Kafka events), we could have followed this approach:
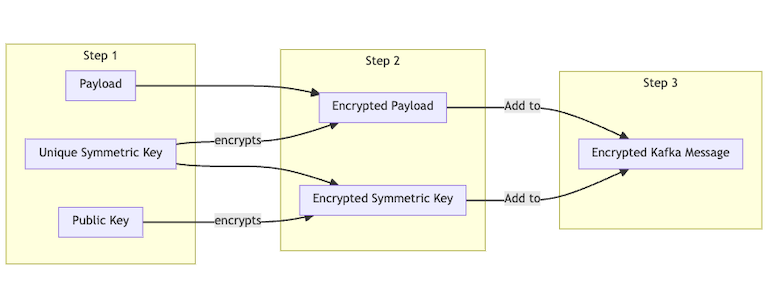
And when the data gets to the data lake, the data team would decrypt as follows:
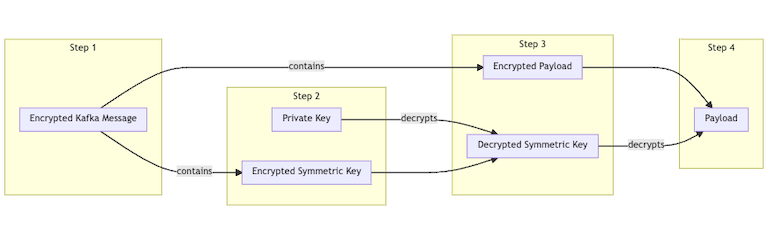
Using this approach would allow us to automatically encrypt larger payloads with symmetric encryption, and safely send the symmetric key by asymmetrically encrypting it. This is how SSL works.
In terms of constructing the event payloads, it’s important to include an additional timestamp field in the payload whenever you’re sending data about a database record. By including our own timestamp, we were able to encode more accurate domain-level event timing, instead of relying on the Kafka event emission timestamp. Our data teams used the payload timestamp rather than the default event timestamp to build out the analytics and metrics. Adding the additional payload timestamp builds extra resiliency into the events as we can easily resend them anytime if any event is lost and ensure it does not alter any time-based metrics.
Getting to MVP and Beyond
Despite all the unknowns and moving pieces related to legal considerations and back end changes, we needed to make progress on the front-end design. The sooner we could present an MVP, the sooner we’d get actionable feedback that we could use to iterate the design. When first starting on the project, the only things that were firmly established were:
- Data integrity is key—what we show to employees matters.
- Employees should be able to use sliders to change their allocations.
- It needed to be accessible.
- It needed to work on mobile browsers.
- There will be some regional regulatory differences (but we didn’t know exactly what they would be).
- There would be some differences based on types of employment (again, not fully defined yet).
- We would need to support multiple languages and locales, including support for a number of different local currencies (exactly which ones were TBD).
- This was V1 of a new system that will continue to grow and needs to be extensible.
- We would need to build and integrate answers to all of these questions concurrently.
We knew that we would be iterating heavily and would likely need to pivot quickly as new information became available, and as we pivoted we needed to be confident that employees across every region and every role saw correct information. Luckily, we thrive on change at Shopify, so we know that uncertainty doesn’t need to be the enemy of progress. To make sure we were prepared for whatever changes came our way, we established a handful of key principles that would inform important decisions early on, like our choice of technical stack, how we defined our backlog, and how we structured the code. These principles were:
- Optimize for parallelization. We needed to be able to make as much progress as possible, as quickly as possible. To do this, we needed to expand the surface area that we had to work with in order to give enough room for each contributor to work with. The better job we did with this, the more developers we could bring into the project early on.
- Single source of truth for data and calculations. If we were to work with multiple people and with requirements that became clearer day by day, we couldn’t risk having duplication of key data and calculations spread throughout the page. As the requirements changed, anything we failed to update could risk showing an employee incorrect information.
- Optimize for iteration. Having a single source of truth for the data allowed us to create an abstraction around the complexity surrounding the calculations, giving us data that we could plug and play throughout the UI. For any data or functionality that wasn’t yet final, it provided us with the ability to create an easy-to-consume interface enforced by contracts, similar to the ones we had between the back end and the front end. We could return dummy data and stub out event handlers, allowing the business logic to evolve separately from the UI and layout it was used in. Having that, we then needed the right tooling to allow us to iterate quickly on layouts. We chose Tailwind as it provided us with the utilities we needed to do this quickly and intuitively.
As we got to work on the front end, our scrappy whiteboard drawings started to evolve into early illustrations the ended up looking not too far from the final product:
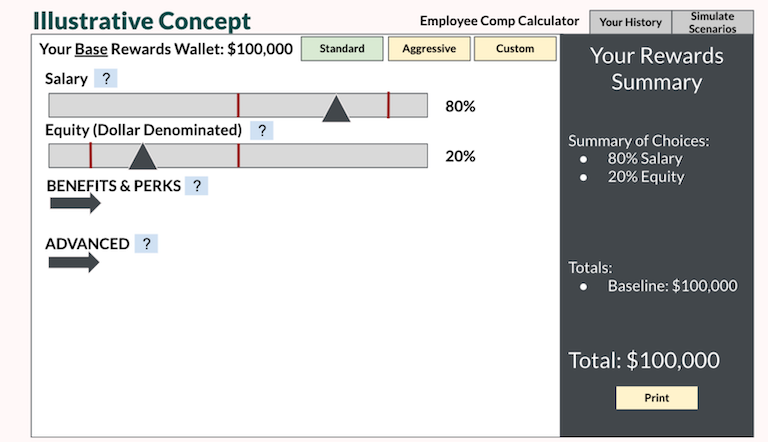
The tool itself was relatively simple on the front end. The key was getting it to a functional state which accounted for regional and employee-type differences, with opportunity for future extensibility.
State Management for a Single Source of Truth
On the front end, we had two main sets of state that needed to be managed: API data provided by the back end about the user and form state for their selections.
API State
Throughout development, the queries we had to do varied quite a bit as requirements evolved and new regional or employee type differences came up. We only needed to query for this data upon page load as most of it represents information that changes infrequently, like employee name and role, certainly not things that would change during a single user session which couldn't be fixed with a quick page reload. The data would also be used throughout the entire page, as we would derive certain properties from it, like the label for the salary compensation of the employee. This led us to create a React Context to provide the data to the React tree. In order to isolate the changing requirements, we were intentional about having a single provider for the data of all the queries, assembled together in one place. This provided the UI layer with a stable platform of iteration similar to the contracts we established with the back end team while also leaving us with a single file to update as data requirements changed.
Due to the small sizes of our request payloads and to optimize for rapid iteration, we went with a naive but effective approach of having the context provider run each of the queries upon mounting. To keep things maintainable we made sure to extract the queries themselves to their own hooks, leaving the provider with the responsibility of calling each of them and stitching together the result, including any calculated properties, defaults, or fallbacks.
Next, continuing in the spirit of rapid iteration we included our new context provider in the Providers component at the top level of the application, providing it for all routes. In the long-term this could lead to some queries being done for pages that don't need it, or unnecessary query waterfalls, etc, but given the small team we had and the knowledge that none of these would be problems for V1, we intentionally kept the naive solution in order to be able to prioritize progress on the rest of the project.
Dynamic State
With the API data loaded, the other state that needed to be managed was the employee allocation form state. Driven by the sliders and used to generate the summary table (which includes additional information during the confirmation steps), this particular part of the state application needed to be very flexible to allow us to account for all the regional and employee type differences, and also provide us with opportunities for extensibility in the far future. Knowing there would be many state fields, all of which would likely interact with each other as employees made changes on the screen, (for example, increasing base salary impacts the total equity available to split between options and RSUs, resetting the form would update all fields) we opted to use the (React recommended) reducer pattern using useReducer.
We had a few minor concerns about the reducer pattern to start out with. First, we weren't certain whether the final product would warrant the complexity the reducer pattern adds, like in the event we simplified the functionality and only needed a few event handlers. We also had maintainability concerns with having the dispatch logic spread throughout the component tree when having to quickly iterate on UI changes. We solved this with the following abstraction:
Typescript plays really well with the reducer pattern. Being able to do all of the above with type safety was absolutely critical when doing clean up of anything that needed to be removed as we iterated as it provided us with errors to do thorough clean up as quickly as possible. For example, we were able to leverage union types to define a type for the actions supported by the reducer like so:
This allowed us to provide a clean, stable interface to the UI components consuming the hook. We were able to use mocked values and stubbed functionality to allow the business logic to be built in parallel with the UI by two separate developers at the same time. Similarly, we were able to parallelize the work for the UserProvider and the individual queries. Having the return types for each of the hooks helped enforce the contract we had established with the back-end team and kept mock data up to date as the contracts evolved. Here’s a high-level pseudocode example of how we managed the mock implementations for the data hooks:
The mocks were also incredibly useful as we were able to set artificial delays to test the page under different conditions.
Ultimately, the abstractions we defined and the contracts we used to enforce them proved to be absolutely critical to our ability to execute on the ambitious timelines of this project. To inform how we thought about prioritizing our time, we set for a goal for ourselves to have a fully functional end-to-end integration of the back end with the (still ugly) front end near the halfway point on the project to give us a comfortable margin to do as much polish as possible and handle any new edge cases that came up. Within the first few weeks of the project, the contracts we had established allowed us to have developers working full force on user authentication, integration with the translation platform, form business logic, slider UI and interactions and the app frame for navigation at the same time, at nearly all hours of the day between our team members in North America and those in Europe. Naturally, the other thing that proved crucial was frequent, intentional communication. When dealing with constant change and uncertainty, being on the same page was important to avoid miscommunications and especially avoid wasted effort. Luckily, being a company that is Digital by Design, the team had already bought into embracing asynchronous collaboration. The power of a shared understanding and mindset allowed us to jump in and contribute with surprisingly little friction.
Onward
Now that V1 has been released to the company, we look to the future. A project like this doesn't ship in such a short amount of time without making important trade-offs. Technical debt is often talked about negatively in the software industry, but it's important to remember that it can also be one of the highest leverage tools at our disposal when used thoughtfully and intentionally. Saying yes to the wrong thing at the wrong time is often the difference between finishing and not.
Throughout the project, the team took many notes to document any technical or design debt we came across, decisions that needed to be made in the future and left behind as much context as possible behind the explorations and prototypes created to help inform future iterations.
We’re really proud of the first version of Flex Comp and the way people from nearly every team at Shopify came together to build it. This marks an exciting first step—with more to come—to tie our rewards more closely to our mission, not the market.
Contributors
Eric Poirier is a Technical Lead for Shopify’s HR Technology Team. He is product manager for the Rewards Wallet and oversaw its integration with downstream payroll and equity systems.
Omas Abdullah is a Development Manager at Shopify.
Rony Besprozvanny is a Senior Developer at Shopify.
David Buckley is a Senior Developer at Shopify.
Chris Poirier is a Senior Front End Developer at Shopify.
Heitor Gama is a Data Scientist at Shopify.
If building systems from the ground up to solve real-world problems interests you, our Engineering blog has stories about other challenges we have encountered. Visit our Engineering career page to find out about our open positions. Join our remote team and work (almost) anywhere. Learn about how we’re hiring to design the future together—a future that is digital by design.