


By Rodrigo Saito, Akshay Suryawanshi, and Jeremy Cole
KateSQL is Shopify’s custom-built Database-as-a-Service platform, running on top of Google Cloud’s Kubernetes Engine (GKE), currently manages several hundred production MySQL instances across different Google Cloud regions and many GKE Clusters.
Earlier this year, we found a performance related issue with KateSQL: some Kubernetes Pods running MySQL would start up and shut down slower than other similar Pods with the same data set. This partially impaired our ability to replace MySQL instances quickly when executing maintenance tasks like config changes or upgrades. While investigating, we found several factors that could be contributing to this slowness.
The root cause was a bug in the Linux kernel memory cgroup controller. This post provides an overview of how we investigated the root cause and leveraged Shopify’s partnership with Google Cloud Platform to help us mitigate it.
The Problem
KateSQL has an operational procedure called instance replacement. It involves creating a new MySQL replica (a Kubernetes Pod running MySQL) and then stopping the old one, repeating this process until all the running MySQL instances in the KateSQL Platform are replaced. KateSQL’s instance replacement operations revealed inconsistent MySQL Pod creation times, ranging from 10 to 30 minutes. The Pod creation time includes the time needed to:
- spin up a new GKE node (if needed)
- create a new Persistent Disk with data from the most recent snapshot
- create the MySQL Kubernetes Pod
- initialize the
mysql-initcontainer (which completes InnoDB crash recovery) - start the
mysqldin themysqlcontainer.
We started by measuring the time of the mysql-init container and the MySQL startup time, and then compared the times between multiple MySQL Pods. We noticed a huge difference between these two MySQL Pods that had the exact same resources (CPU, memory, and storage) and dataset:
|
KateSQL instance |
Initialization |
Startup |
|
katesql-n4sx0 |
2120 seconds |
1104 seconds |
|
katesql-jxijq |
74 seconds |
17 seconds |
Later, we discovered that the MySQL Pods with slow creation time also showed gradual decrease in performance. Evidence of that was an increased number of slow queries for queries that utilized temporary memory tables:
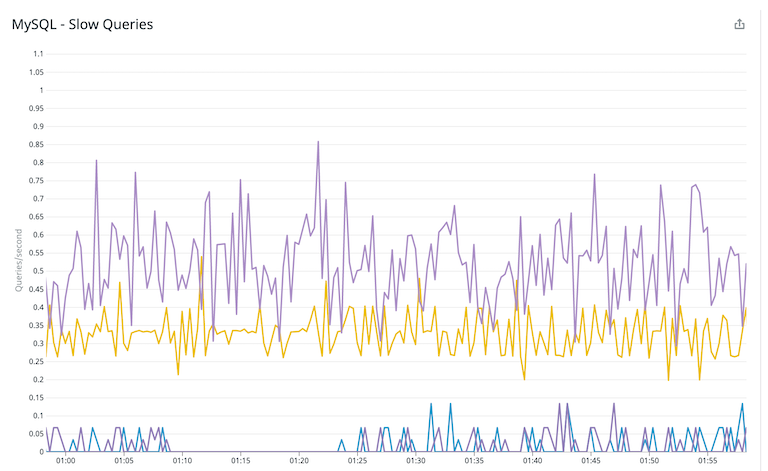
Immediate Mitigation
A quick spot-check analysis revealed that newly provisioned Kubernetes cluster nodes performed better than those that were up and running for a few months. Having this information in hand, we started our first mitigation strategy for this problem that was to replace the older Kubernetes cluster nodes with new ones using the following steps:
- Cordon (disallow any new Pods) the older Kubernetes cluster nodes.
- Replace instances using KateSQL to move MySQL Pods to new Kubernetes nodes, allowing GKE to autoscale the cluster by adding new cluster nodes as necessary.
- Once instances are moved to new Kubernetes nodes, drain the cordoned cluster nodes to scale down the cluster (automatically, through GKE autoscaler).
This strategy was applied to production KateSQL instances, and we observed performance improvements on the new MySQL Pods.
Further Investigation
We began a deeper analysis to understand why newer cluster nodes performed better than older cluster nodes. We ruled out differences in software versions like kubelet, the Linux kernel, Google’s Container-optimized OS (COS), etc. Everything was the same, except their uptimes.
Next, we started a resource analysis of each resource subsystem to narrow down the problem. We ruled out the storage subsystem, as the MySQL error log provided a vital clue as to where the slowness was So we examined timestamps from InnoDB’s Buffer Pool initialization:
We analyzed the MySQL InnoDB source code to understand the operations involved during InnoDB’s Buffer Pool initialization. Most importantly, memory allocation during its initialization is single-threaded, as confirmed using top to show it consuming approximately 100% CPU usage. We subsequently captured strace output of the mysqld process while it was starting up
We see that each mmap() system call took around 100 ms to allocate approximately 128MB sized chunks, which in our opinion is terribly slow for the memory allocation process.
We also did an On-CPU perf capture during this initialization process, below is the snapshot of the flamegraph:

Quick analysis of the flamegraph shows how MySQL (InnoDB) buffer pool initialization task is delegated to the memory allocator (jemalloc in our case) that then spends most of its time in a kernel function called mem_cgroup_commit_charge.
We further analyzed what the mem_cgroup_commit_charge function does: it seems to be part of memcg (memory control group) and is responsible for charging (claiming ownership of) pages from one cgroup (unused/dead or root cgroup) to the cgroup of the allocating process. Unfortunately, memcg isn’t well documented, so it’s hard to understand what’s causing the slow down.
Another unusual thing we spotted (using the slabtop command) was the abnormally high dentry cache, sometimes around 20GB for about 64 pods running on a given Kubernetes Cluster node:
While investigating if a large dentry cache could be slowing the entire system down, we found this post by sysdig that provided useful information. After further analysis following the steps from the post, we confirmed that it wasn’t the same case as we were experiencing. However, we noticed immediate performance improvements (similar to a restarted Kubernetes cluster node) after dropping the dentry cache using the following command:
echo 2 > /proc/sys/vm/drop_caches
Continuing the unusual slab allocation investigation, we ruled out any of its side effects, like memory defragmentation, since enough higher-order free pages were available (which was verified using the output of /proc/buddyinfo). Also, this memory is reclaimable during memory pressure events.
A Breakthrough
Going through various bug reports related to cgroups, we found a command to list the number of cgroups in a system:
We compared the memory cgroup’s value of a good node and an affected node. We concluded that approximately 50K memory cgroups is more than expected even with some of our short-lived tasks! This indicated to us that there could be a cgroup leak. It also helped make sense of the perf output that we had flamegraphed previously. There could be a performance impact if the cgroup commit charge has to traverse through many cgroups for each page charge. We also saw that it locks page cache least recently used (LRU) list from source code analysis.
We evaluated a few more bug reports and articles, especially the following:
- A bug report unrelated to Kubernetes but pointing to the underlying cause related to cgroups. This bug report also helped point to the fix that was available for such an issue.
- An article on lwn.net related to almost our exact issue. A must read!
- A related workaround to the problem in Kubernetes.
- A thread in the Linux kernel mailing list that helped a lot.
These posts were a great signal that we were on the right track to understanding the root cause of the problem. To confirm our findings and understand if a symptom of this cgroup leak, that wasn’t yet observed in the Linux community, we met with Linux kernel engineers at Google.
We evaluated an affected node, and the nature of the problem. The Google engineers were able to confirm that we were in fact hitting another side-effect of reparent slab memory on cgroup removal.
To Prove the Hypothesis
After evaluating the problem, we tested a possible solution to this problem. We invoked a switch file for the kubepods cgroup (the parent cgroup for Kubernetes pods) to force it to empty zombie/dead cgroup:
$ echo 1 | sudo tee /sys/fs/cgroup/memory/kubepods/memory.force_empty
This caused the number of memory cgroups to decrease rapidly to only approximately 1800 memory cgroups that is in line with a good node as previously compared:
We quickly tested a MySQL Pod restart to see if there were any improvements in startup time performance. An 80G InnoDB buffer pool was initialized in five seconds:
A Possible Workaround and Fixes
There were multiple workarounds and fixes for this problem that we evaluated with engineers from Google:
- Rebooting or cordoning the cluster node VM, identifying them by monitoring
/proc/cgroups output. - Set up a cronjob to drop SLAB and page caches. It’s an old school DBA/sysadmin technique that might work but could have a performance penalty on read IO.
- Short-lived Pods moved to a dedicated nodepool to isolate them from the more critical parts like MySQL Pods.
-
echo 1 > /sys/fs/cgroup/memory/memory.force_emptyin apreStophook of a short-lived Pod. - Upgrade to COS 85 that has upstream fixes to cgroup SLAB re-parenting bugs. Upgrading from GKE 1.16 to 1.18 should get us the Linux kernel 5.4 with the relevant bug fixes.
Since we were due a GKE version upgrade, we created new GKE clusters with GKE 1.18 and started creating new MySQL Pods on those new clusters. After several weeks of running on GKE 1.18, we saw consistent MySQL InnoDB Buffer Pool initialization time and query performance:

This was one of the lengthiest investigations that the Database Platform group has carried out at Shopify. The time taken to identify the root cause was due to the nature of the problem, difficult reproducibility, and absolutely no out-of-the-book methodology to follow. However, there are multiple ways to solve the problem and that’s a very positive outcome.
Special thanks to Roman Gushchin from Facebook’s Kernel Engineering team, whom we connected with via LinkedIn to discuss this problem, and Google’s Kernel Engineering team who helped us confirm and solve the root cause of the problem.
Rodrigo Saito is a Senior Production Engineer in the Database Backend team, where he primarily works on building and improving KateSQL, Shopify's Database-as-a-Service, using his more than a decade of Software Engineering experience. Akshay Suryawanshi is a Staff Production Engineer in the Database Backend team, who helped build KateSQL at Shopify along-with Jeremy Cole, who is a Senior Staff Production Engineer in the larger Database Platform group. Both of them brings decades of Database Administration and Engineering experience to manage Petabyte scale infrastructure.
Wherever you are, your next journey starts here! If building systems from the ground up to solve real-world problems interests you, our Engineering blog has stories about other challenges we have encountered. Intrigued? Visit our Engineering career page to find out about our open positions and learn about Digital by Default.