


Databases are a key scalability bottleneck for many web applications. But what if you could make a small change to your database design that would unlock massively more efficient data access? At Shopify, we dusted off some old database principles and did exactly that with the primary Rails application that powers online stores for over a million merchants. In this post, we’ll walk you through how we did it, and how you can use the same trick to optimize your own applications.
Background
A basic principle of database design is that data that is accessed together should be stored together. In a relational database, we see this principle at work in the design of individual records (rows), which are composed of bits of information that are often accessed and stored at the same time. When a query needs to access or update multiple records, this query will be faster if those rows are “near” to each other. In MySQL, the sequential ordering of rows on disk is dictated by the table’s primary key.
Active Record is the portion of the Rails application framework that abstracts and simplifies database access. This layer introduces database practices and conventions that greatly simplify application development. One such convention is that all tables have a simple automatically incrementing integer primary key, often called `id`. This means that, for a typical Rails application, most data is stored on disk strictly in the order the rows were created. For most tables in most Rails applications, this works just fine and is easy for application developers to understand.
Sometimes the pattern of row access in a table is quite different from the insertion pattern. In the case of Shopify’s core API server, it is usually quite different, due to Shopify’s multi-tenant architecture. Each database instance contains records from many shops. With a simple auto-incrementing primary key, table insertions interleave the insertion of records across many shops. On the other hand, most queries are only interested in the records for a single shop at a time.
Let’s take a look at how this plays out at the database storage level. We will use details from MySQL using the InnoDB storage engine, but the basic idea will hold true across many relational databases. Records are stored on disk in a data structure called a B+ tree. Here is an illustration of a table storing orders, with the integer order id shown, color-coded by shop:

Individual records are grouped into pages. When a record is queried, the entire page is loaded from disk into an in-memory structure called a buffer pool. Subsequent reads from the same page are much faster while it remains in the buffer pool. As we can see in the example above, if we want to retrieve all orders from the “yellow” shop, every page will need loading from disk. This is the worst-case scenario, but it turned out to be a prevalent scenario in Shopify’s main operational database. For some of our most important queries, we observed an average of 0.9 pages read per row in the final query result. This means we were loading an entire page into memory for nearly every row of data that we needed!
The fix for this problem is conceptually very simple. Instead of a simple primary key, we create a composite primary key [shop_id, order_id]. With this key structure, our disk layout looks quite different:
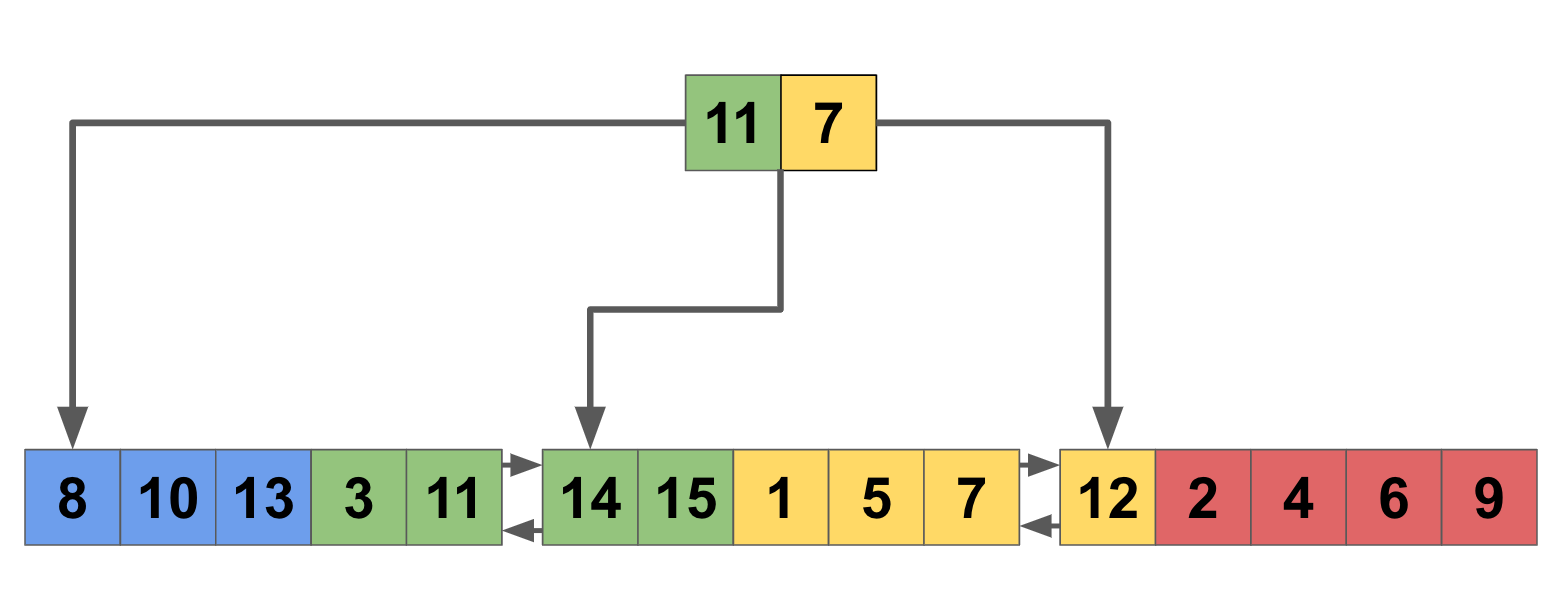
Records are now grouped into pages by shop. When retrieving orders for the “yellow” shop, we read from a much smaller set of pages (in this example it’s only one page less, but imagine extrapolating this to a table storing records for 10,000 shops and the result is more profound).
So far, so good. We have an obvious problem with the efficiency of data access and a simple solution. For the remainder of this article, we’ll go through some of the implementation details and challenges we came across with rolling out composite primary keys in our main operational database, along with the impact for our Ruby on Rails application and other systems directly coupled to our database. We will continue using the example of an “orders” table, both because it is conceptually simple to understand. It also turned out to be one of the critical table names that we applied this change to.
Introducing Composite Primary Keys
The first challenge we faced with introducing composite primary keys was at the application layer. Our framework and application code contained various assumptions about the table’s primary key. Active Record, in particular, assumes an integer primary key, and although there is a community gem to monkey-patch this, we didn’t have confidence that this approach would be sustainable and maintainable in the future. On deeper analysis, it turned out that nearly all such assumptions in application layer code continued to hold if we changed the `id` column to be an auto-incrementing secondary key. We can leave the application layer blissfully unaware of the underlying database schema by forcing Active Record to treat the `id` column as a primary key:
class Order < ApplicationRecord
self.primary_key = :id
.. remainder of order model ...
end
Here is the corresponding SQL table definition:CREATE TABLE `orders` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`shop_id` bigint(20) NOT NULL,
… other columns ...
PRIMARY KEY (`shop_id`,`id`),
KEY `id` (`id`)
… other secondary keys ...
)
Note that we chose to leave the secondary index as a non-unique key here. There is some risk to this approach because it is possible to construct application code that results in duplicate models with the same id (but with different shop_id in our case). You can opt for safety here and make a unique secondary key on id. We took this approach because the method we use for live schema migrations is prone to deadlock on tables containing multiple unique constraints. Specifically, we use Large Hadron Migrator (LHM), which uses MySQL triggers to copy records into a shadow table during migrations. Unique constraints are enforced in InnoDB through an exclusive table-level write lock. Since there are two tables accepting writes, each containing two exclusive locks, all of the necessary deadlock conditions are present during migration. You may be able to keep a unique constraint on `id` if any of the following are true:
- You don’t perform live migrations on your application.
- Your migrations don’t use SQL triggers (such as the default Rails migrations).
- The write throughput on the table is low enough that a low volume of deadlocks is acceptable for your application.
- The code path for writing to this table is resilient to database transaction failures.
The remaining area of concern is any data infrastructure that directly accesses the MySQL database outside of the Rails application layer. In our case, we had three key technologies that fell into this category:
- Our database schema migration infrastructure, already discussed above.
- Our live data migration system, called Ghostferry. Ghostferry moves data across different MySQL instances while the application is still running, enabling load-balancing of sharded data across multiple databases. We implemented support for composite primary keys in ghostferry as part of this work, by introducing the ability to specify an alternate column for pagination during migration.
- Our data warehousing system does both bulk and incremental extraction of MySQL tables into long term storage. Since this system is proprietary to Shopify we won’t cover this area further, but if you have a similar data extraction system, you’ll need to ensure it can accommodate tables with composite primary keys.
Results
Before we dig into specific results, a disclaimer: every table and corresponding application code is different, so the results you see in one table do not necessarily translate into another. You need to carefully consider your data’s access patterns to ensure that the primary key structure produces the optimal clustering for those access patterns. In our case of a sharded application, clustering the data by shop was often the right answer. However, if you have multiple closely connected data models, you may find another structure works better. To use a common example, if an application has “Blog” and “BlogPost” models, a suitable primary key for the blog_posts table may be (blog_id, blog_post_id). This is because typical data access patterns will tend to query posts for a single blog at once. In some cases, we found no overwhelming advantage to a composite primary key because there was no such singular data access pattern to optimize for. In one more subtle example, we found that associated records tended to be written within the same transaction, and so were already sequentially ordered, eliminating the advantage of a composite key. To extend the previous blog example, imagine if all posts for a single blog were always created in a single transaction, so that blog post records were never interleaved with insertion of posts from other blogs.
Returning to our leading example of an “orders” table, we measured a significant improvement in database efficiency:
- The most common queries that consumed most database capacity had a 5-6x improvement in elapsed query time.
- Performance gains corresponded linearly with a reduction in MySQL buffer pool page reads per query. Adding a composite key on our single most queried table reduced the median buffer pool reads per query from 1.8 to 1.2.
- There was a dramatic improvement in tail latency for our slowest queries. We maintain a log of slow queries, which showed a roughly 80% reduction in distinct queries relating to the orders table.
- Performance gains varied greatly across different kinds of queries. The most dramatic improvement was 500x on a particularly egregious query. Most queries involving joins saw much lower improvement due to the lack of similar data clustering in other tables (we expect this to improve as more tables adopt composite keys).
- A useful measure of aggregate improvement is to measure the total elapsed database time per day, across all queries involving the changed table. This helps to add up the net benefit on database capacity across the system. We observed a reduction of roughly one hour per day, per shard, in elapsed query time from this change.
There is one notable downside on performance that is worth clearly calling out. A simple auto-incrementing primary key has optimal performance on insert statements because data is always clustered in insertion order. Changing to a composite primary key results in more expensive inserts, as more distinct database pages need to be both read and flushed to disk. We observed a roughly 10x performance degradation on inserts by changing to a composite primary key. Most data are queried and updated far more often than inserted, so this tradeoff is correct in most cases. However, it is worth keeping this in mind if insert performance is a critical bottleneck in your system for the table in question.
Wrapping Up
The benefits of data clustering and the use of composite primary keys are well-established techniques in the database world. Within the Rails ecosystem, established conventions around primary keys mean that many Rails applications lose out on these benefits. If you are operating a large Rails application, and either database performance or capacity are major concerns, it is worth exploring a move to composite primary keys in some of your tables. In our case, we faced a large upfront cost to introduce composite primary keys due to the complexity of our data infrastructure, but with that cost paid, we can now introduce additional composite keys with a small incremental effort. This has resulted in significant improvements to query performance and total database capacity in one of the world’s largest and oldest Rails applications.
Wherever you are, your next journey starts here! If building systems from the ground up to solve real-world problems interests you? Visit our Engineering career page to find out about our open positions and learn about Digital by Default.