


Humans generate a lot of data. Every two days we create as much data as we did from the beginning of time until 2003! The International Data Corporation estimates the global datasphere totaled 33 zettabytes (one trillion gigabytes) in 2018. The estimate for 2025 is 175 ZBs, an increase of 430%. This growth is challenging organizations across all industries to rethink their data pipelines.
The nature of data usage is problem driven, meaning data assets (tables, reports, dashboards, etc.) are aggregated from underlying data assets to help decision making about a particular business problem, feed a machine learning algorithm, or serve as an input to another data asset. This process is repeated multiple times, sometimes for the same problems, and results in a large number of data assets serving a wide variety of purposes. Data discovery and management is the practice of cataloguing these data assets and all of the applicable metadata that saves time for data professionals, increasing data recycling, and providing data consumers with more accessibility to an organization’s data assets.
To make sense of all of these data assets at Shopify, we built a data discovery and management tool named Artifact. It aims to increase productivity, provide greater accessibility to data, and allow for a higher level of data governance.
The Discovery Problem at Shopify
Data discovery and management is applicable at every point of the data process:
| Acquire |
|
| Transform |
|
| Model |
|
| Apply |
|
High level data process
The data discovery issues at Shopify can be categorized into three main challenges: curation, governance, and accessibility.
Curation
“Is there an existing data asset I can utilize to solve my problem?”
Before Artifact, finding the answer to this question at Shopify often involved asking team members in person, reaching out on Slack, digging through GitHub code, sifting through various job logs, etc. This game of information tag resulted in multiple sources of truth, lack of full context, duplication of effort, and a lot of frustration. When we talked to our Data team, 80% felt the pre-Artifact discovery process hindered their ability to deliver results. This sentiment dropped to 41% after Artifact was released.
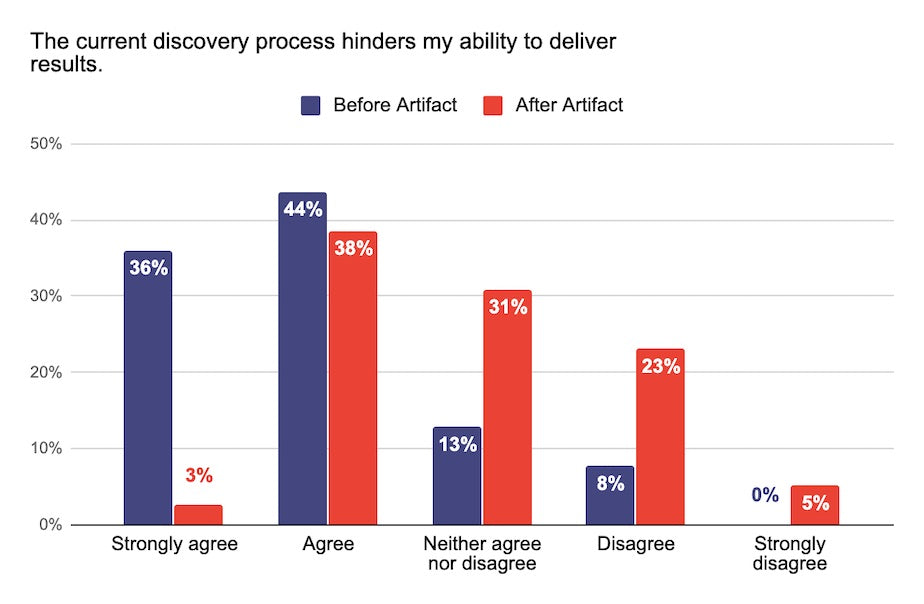
The current discovery process hinders my ability to deliver results survey answers
Governance
“Who is going to be impacted by the changes I am making to this data asset?”
Data governance is a broad subject that encompasses many concepts, but our challenges at Shopify are related to lack of granular ownership information and change management. The two are related, but generally refer to the process of managing data assets through their life cycle. The Data team at Shopify spent a considerable amount of time understanding the downstream impact of their changes, with 16% of the team feeling they understood how their changes impacted other teams:

I am able to easily understand how my changes impact other teams and downstream consumers survey answers
Each data team at Shopify practices their own change management process, which makes data asset revisions and changes hard to track and understand across different teams. This leads to loss of context for teams looking to utilize new and unfamiliar data assets in their workflows. Artifact has helped each data team understand who their downstream consumers are, with 46% of teams now feeling they understand the impact their changes have on them.
Accessibility
“How many merchants did we have in Canada as of January 2020?”
Our challenge here is surfacing relevant, well documented data points our stakeholders can use to make decisions. Reporting data assets are a great way to derive insights, but those insights often get lost in Slack channels, private conversations, and archived powerpoint presentations. Lack of metadata surrounding these report/dashboard insights directly impacts decision making, causes duplication of effort for the Data team, and increases the stakeholders’ reliance on data as a service model that in turn inhibits our ability to scale our Data team.
Our Solution: Artifact, Shopify’s Data Discovery Tool
We spent a considerable amount of time talking to each data team and their stakeholders. On top of the higher level challenges described above, there were two deeper themes that came up in each discussion:
- The data assets and their associated metadata is the context that informs the data discovery process.
- There are many starting points to data discovery, and the entire process involves multiple iterations.
Working off of these themes, we wanted to build a couple of different entry points to data discovery, enable our end users to quickly iterate through their discovery workflows, and provide all available metadata in an easily consumable and accessible manner.
Artifact is a search and browse tool built on top of a data model that centralizes metadata across various data processes. Artifact allows all teams to discover data assets, their documentation, lineage, usage, ownership, and other metadata that helps users build the necessary data context. This tool helps teams leverage data more effectively in their roles.
Artifact’s User Experience

Artifact Landing Page
Artifact’s landing page offers a choice to either browse data assets from various teams, sources, and types, or perform a plain English search. The initial screen is preloaded with all data assets ordered by usage, providing users who aren’t sure what to search for a chance to build context before iterating with search. We include the usage and ownership information to give the users additional context: highly leveraged data assets garner more attention, while ownership provides an avenue for further discovery.

Artifact Search Results
Artifact leverages Elasticsearch to index and store a variety of objects: data asset titles, documentation, schema, descriptions, etc. The search results provide enough information for users to decide whether to explore further, without sacrificing the readability of the page. We accomplished this by providing the users with data asset names, descriptions, ownership, and total usage.

Artifact Data Asset Details
Clicking on the data asset leads to the details page that contains a mix of user and system generated metadata organized across horizontal tabs, and a sticky vertical nav bar on the right hand side of the page.
The lineage information is invaluable to our users as it:
- Provides context on how a data asset is utilized by other teams.
- Lets data asset owners know what downstream data assets might be impacted by changes.
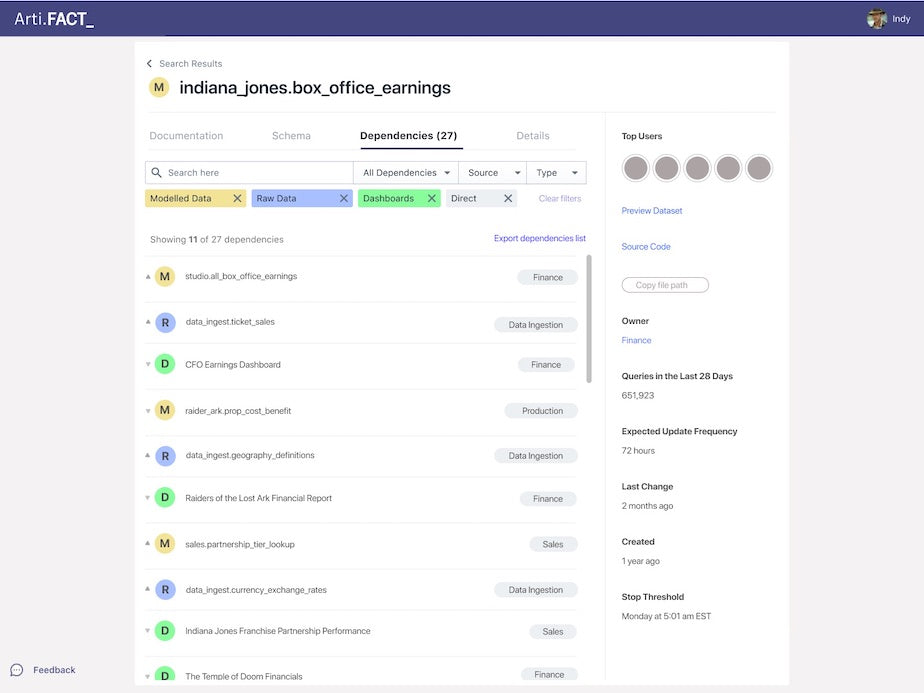
Artifact Data Asset Lineage
This lineage feature is powered by a graph database, and allows the users to search and filter the dependencies by source, direction (upstream vs. downstream), and lineage distance (direct vs. indirect).
Artifact’s Architecture
Before starting the build, we decided on these guiding principles:
- There are no perfect tools; instead solve the biggest user obstacles with the simplest possible solutions.
- The architecture design has to be generic enough to easily allow future integrations and limit technical debt.
- Quick iterations lead to smaller failures and clear, focused lessons.
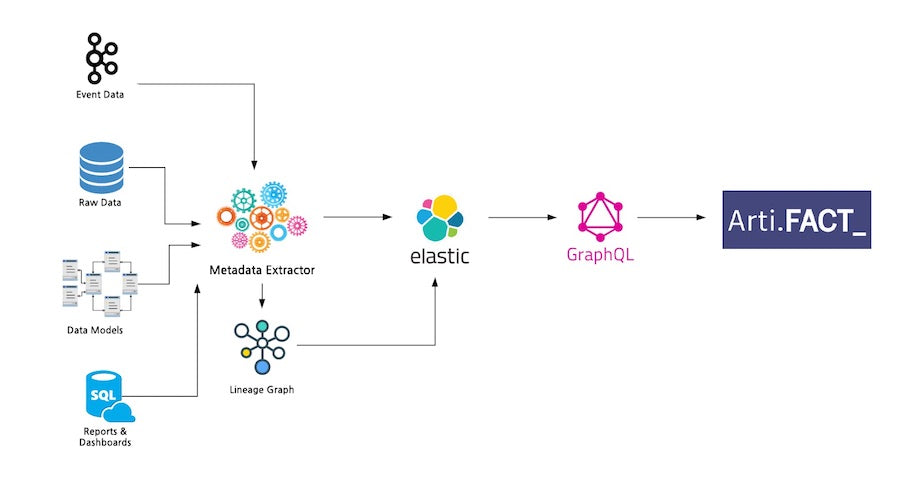
Artifact High Level Architecture
With these in mind, we started with a generic data model, and a simple metadata ingestion pipeline that pulls the information from various data stores and processes across Shopify. The metadata extractor also builds the dependency graph for our lineage feature. Once processed, the information is stored in Elasticsearch indexes, and GraphQL APIs expose the data via an Apollo client to the Artifact UI.
Trade-offs
Buy vs. Build
The recent growth in data, and applications utilizing data, has given rise to data management and cataloguing tooling. We researched a couple of enterprise and open source solutions, but found the following challenges were common across all tools:
- Every organization’s data stack is different. While some of the upstream processes can be standardized and catalogued appropriately, the business context of downstream processes creates a wide distribution of requirements that are near impossible to satisfy with a one-size-fits-all solution.
- The tools didn’t capture a holistic view of data discovery and management. You are able to effectively catalogue some data assets. However, cataloguing the processes surrounding the data assets were lacking: usage information, communication & sharing, change management, etc.
- At Shopify, we have a wide range of data assets, each requiring its own set of metadata, processes, and user interaction. The tooling available in the market doesn’t offer support for this type of variety without heavy customization work.
With these factors in mind, the buy option would’ve required heavy customization, technical debt, and large efforts for future integrations. So, we went with the build option as it was:
- The best use case fit.
- Provided the most flexibility.
- Left us with full control of how much technical debt we take on.
Metadata Push vs. Pull
The architecture diagram above shows the metadata sources our pipeline ingests. During the technical design phase of the build, we reached out to the teams responsible for maintaining the various data tools across the organization. The ideal solution was for each tool to expose a metadata API for us to consume. All of the teams understood the value in what we were building, but writing APIs was new incremental work to their already packed roadmaps. Since pulling the metadata was an acceptable workaround and speed to market was a key factor, we chose to write jobs that pull the metadata from their processes; with the understanding that a future optimization will include metadata APIs for each data service.
Data Asset Scope
Our data processes create a multitude of data assets: datasets, views, tables, streams, aliases, reports, models, jobs, notebooks, algorithms, experiments, dashboards, CSVs, etc. During the initial exploration and technical design, we realized we wouldn’t be able to support all of them with our initial release. To cut down the data assets, we evaluated each against the following criteria:
- Frequency of use:how often are the data assets being used across the various data processes?
- Impact to end users:what is the value of each data asset to the users and their stakeholders?
- Ease of integration:what is the effort required to integrate the data asset in Artifact?
Based on our analysis, we decided to integrate the top queryable data assets first, along with their downstream reports and dashboards. The end users would get the highest level of impact with the least amount of build time. The rest of the data assets were prioritized accordingly, and added to our roadmap.
What’s Next for Artifact?
Since its launch in early 2020, Artifact has been extremely well received by data and non-data teams across Shopify. In addition to the positive feedback and the improved sentiment, we are seeing over 30% of the Data team using the tool on a weekly basis, with a monthly retention rate of over 50%. This has exceeded our expectations of 20% of the Data team using the tool weekly, with a 33% monthly retention rate.
Our short term roadmap is focused on rounding out the high impact data assets that didn’t make the cut in our initial release, and integrating with new data platform tooling. In the mid to long term, we are looking to tackle data asset stewardship, change management, introduce notification services, and provide APIs to serve metadata to other teams. The future vision for Artifact is one where all Shopify teams can get the data context they need to make great decisions.
Artifact aims to be a well organized toolbox for our teams at Shopify, increasing productivity, reducing the business owners’ dependence on the Data team, and making data more accessible.
Are you passionate about data discovery and eager to learn more, we’re always hiring! Reach out to us or apply on our careers page.