


Ruby has an explicit goal to make developers happy. Historically, working towards that goal mostly meant having rich syntax and being an expressive programming language—allowing developers to focus on business logic rather than appeasing the language’s rules.
Today, tooling has become a key part of this goal. Many modern languages, such as TypeScript and Rust, have rich and robust tooling to enhance the programming experience. That’s why we built the Ruby LSP, a new language server that makes coding in Ruby even better by providing extra Ruby features for any editor that has a client layer for the LSP. In this article, we’ll cover how we built the Ruby LSP, the features included within it, and how you can install it.
Why a New Language Server?
A few language servers already exist for Ruby: Sorbet, Steep, Typeprof and Solargraph are all implementations of the language server protocol (LSP) specification. The main distinction between them and the Ruby LSP is that the Ruby LSP attempts to provide features as accurately as possible without typechecking the code or requiring type annotations.
Two major goals for the Ruby LSP are performance and stability. Developers tend to have high expectations when it comes to how responsive their editor feels. In order to meet these expectations in Shopify’s Core monolith, the Ruby LSP has to be able to efficiently handle and analyze thousands of files, which may sometimes be thousands of lines long.
Finally, the Ruby LSP is intended to be an opinionated language server, tailored for using Ruby with Rails. Therefore, we have plans to add specific features that can further assist developers in their day to day work using the framework.
How Language Servers Work
Before language servers existed, programming language specific functionality—such as Go to Definition or Auto Formatting—was all implemented in editor plugins. This approach had a series of drawbacks:
- Each editor uses a different programming language and exposes a different API to their plugins, in addition to having different internal designs. This means that plugins cannot be shared between different editors. If we implemented Ruby features for one editor, we’d need to reimplement them all again if we wanted them to work on a different one.
- Because of the point above, programming language communities couldn’t join efforts in improving their developer experience since it was tightly coupled to which editor each person used.
- A specification providing guidelines for which features should be a part of programming language plugins didn’t exist. You couldn’t expect to find the same features for a language when switching editors.
To have support for rich features for each programming language, editors needed at least one plugin for each language providing them. If we wanted to have Ruby features in ten different editors, that meant implementing the same features ten times!
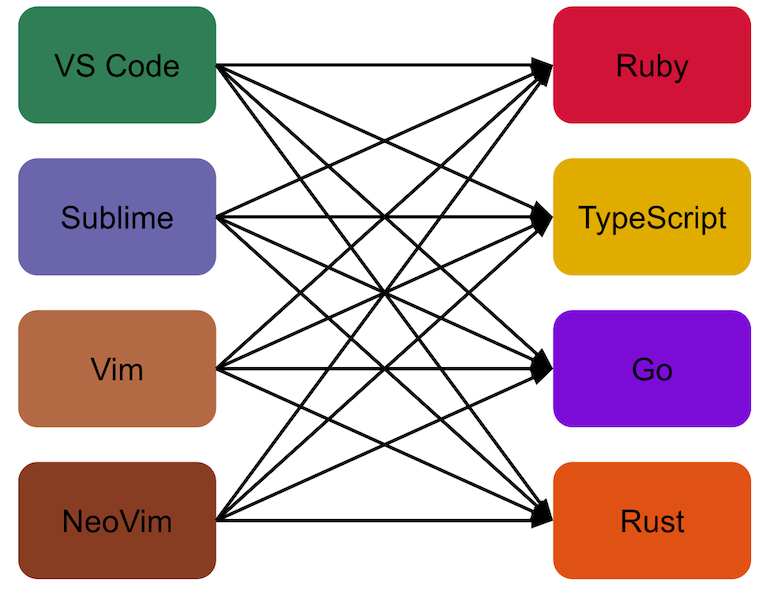
The language server protocol was proposed by the VS Code team at Microsoft to tackle these issues. It’s a specification on how to write background processes that run on the developer’s machine to provide programming language features to any editor. Additionally, it includes a standard set of features that anyone can expect when using language servers.
The editor (client) spawns the background process (server) and keeps handles to the STDIN and STDOUT pipes, which are used to communicate via JSON. For example, when using Go to Definition, the editor sends a JSON request through STDIN asking the language server to find the definition of whatever is currently at the cursor position. The server receives the request, performs the work to find the definition location and then returns that as JSON to the editor via STDOUT. The editor receives the response and translates it into the action that needs to occur (jumping to the right file at the right position where that definition exists).
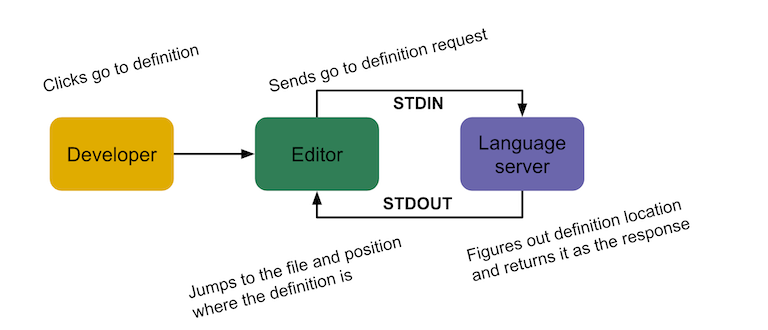
Standardizing request and response formats using JSON breaks the coupling between the editor and the implementation of programming language features. The layer that translates developer actions into JSON requests and JSON responses into behavior (the client layer) is only coupled with the editor it’s implemented for—usually implemented built-in or as a plugin. From the client’s perspective, performing Go to Definition is the same for any programming language since both request and response are the same JSON structure.
The server, on the other hand, is where all of the programming language specifics are implemented, but isn’t concerned at all with which editor is going to connect to it. For example, a Ruby language server is only concerned with how to find definitions, format code or show diagnostics for Ruby code—but those will not differ in any way no matter which editor is using the server.
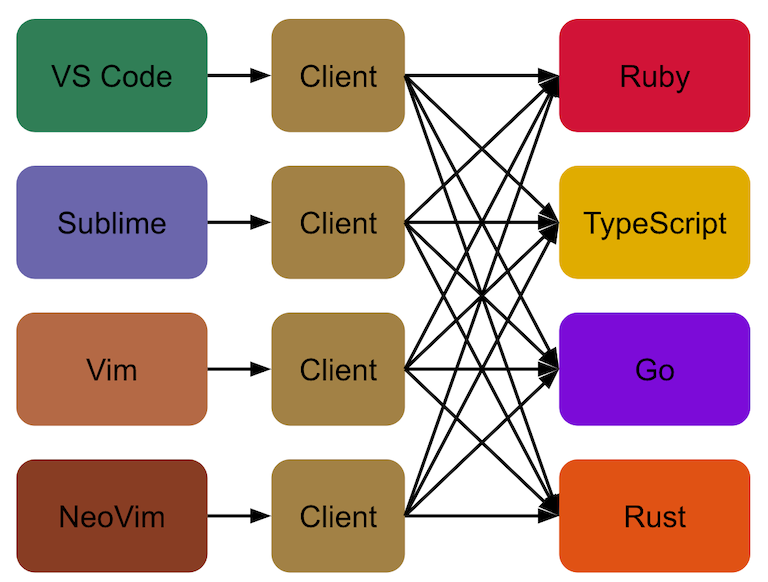
Any features implemented in a language server are available to all editors that implement their own client layer, making it easy for language communities to join efforts in improving their developer experience and to avoid duplicate implementations.
The Ruby LSP
The Ruby LSP, as the name hints at, is an implementation of the protocol for Ruby. It provides extra Ruby features for any editor that has a client layer for the LSP. Let’s dive into how it works, what is currently supported and then we’ll talk about future plans.
How it Understands Ruby Code
In language servers, there are mainly two different types of language feature requests: positional and nonpositional.
Positional requests are features in which the current location of the cursor matters. Go to Definition is the most common example, where the exact placement of the cursor will determine which constant or method you are trying to jump to the definition of.
Conversely , nonpositional requests are features computed for the entire file, and the cursor position does not matter. An example of these requests is Folding Range, which computes all possible places where code can be expanded or collapsed for the entire file that is currently active in the editor.
The approaches to implement these two categories of features are different and each one deserves a dedicated explanation. For this blog post, we will focus on how the Ruby LSP implements nonpositional features—more specifically, the Folding Range request.
Document Synchronization
When a developer is typing code in the editor, the server needs to know about the current state of the files that are open. The process of keeping track of file contents is called document synchronization.
The editor sends notifications to inform the server about relevant document changes. The three basic ones are:
- textDocument/didOpen: sent when a file has been opened in the editor. This notification includes the file URI and the current contents.
- textDocument/didChange: sent when a file is modified (when the user types something). This may include the entire text contents of the file or a list of modifications, depending on how the server is configured.
- textDocument/didClose: sent when a file is closed in the editor’s UI.
It’s the responsibility of the server to use these notifications to maintain a representation of the documents that are opened in the editor. When the server receives feature requests, such as Folding Range, the parameters do not include the contents of the file. Only the URI is sent as a way of identifying which file the editor is referring to. The server must know, at all times, what the contents of each open document are and in what path (URI) they exist.
Parsing Files
When the language server synchronizes documents with the editor, it does so using raw text. After synchronization, we have a string containing the Ruby code in the active file. To be able to properly analyze the code, we need a structure containing rich information describing what Ruby constructs exist in that text.
Parsing that string of Ruby code provides us with an abstract syntax tree (AST), which is an object representation of the code structure. The Ruby LSP uses the Syntax Tree gem (which is an object layer built on top of Ripper, Ruby’s internal parser) to obtain this representation of everything that exists in the code. In the following figure, the left side represents a file opened in the editor and the right side shows an example AST we can get by parsing the code.
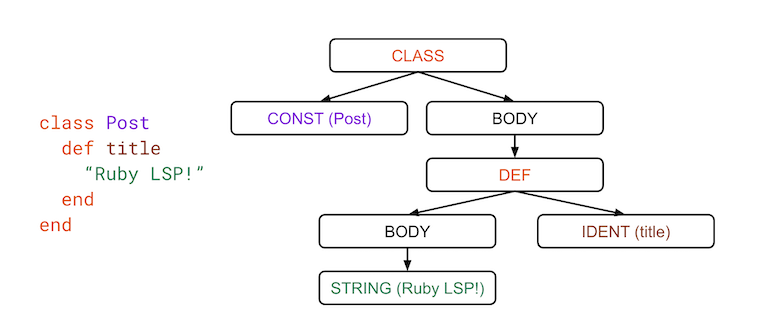
Notice how the AST contains all of the relevant information about the file. We can tell everything that is defined in it as Ruby understands it. All of the modules, classes, methods, variables and any other construct are described by objects containing all of the information related to it in a linked list type of pattern. With the AST in hand, the last step for analyzing a file is going over its structure and collecting data we need.
💡 If you want to learn more about Syntax Tree, check out Kevin Newton’s talk from RubyConf Mini 2022 on YouTube.
Analyzing Structure with Visitors
For analyzing the AST, we must step through everything that is defined in it (every node in the tree) and collect data about what we find. To do this, the Ruby LSP uses the visitor pattern, which is another feature included in Syntax Tree. This design allows us to separate the logic of moving through every single node in the tree from the individual request logic we want to implement.
In the case of our Post class example, we want to allow editors to expand and collapse the code in the class and in the method definition. We need a way to find all of the classes and def nodes to collect them in our list of ranges. According to the specification, the minimum we have to return to the editor as a response is the start line, the end line and the kind of each range.
We’ll start implementing our request by creating a new Folding Range visitor, which inherits from the base one defined in Syntax Tree. It’ll be initialized with the AST (the parsed file) and an empty array of ranges where we’ll accumulate our results.
Running our request implementation means visiting the AST—moving through every node that exists in it—and then returning the array of ranges, where we put the results we encountered along the way.
The last piece of putting this request together is defining what happens when we encounter specific types of nodes. We do that by overriding specific visit methods from the base Syntax Tree visitor to define the behavior we want when we find a particular type of node. For example, overriding visit_class allows us to define behavior that needs to occur every time we find a class definition—and that’s a node we’re interested in folding.
Note that we’re invoking super as the last instruction in that method. We need to invoke the base visitor’s implementation to maintain the default behavior of moving through every node in the AST. Otherwise, our visitor would stop whenever we found a class definition.
Notice how the separation of moving through the AST and the request logic becomes more evident here. The visit method and all of the functionality to allow us to find every node present in the file is all coming from the parent class, whereas the Folding Range logic is all neatly encapsulated in our visitor.
To finalize folding our Post class, we need to handle method definition nodes as well. Similarly to class nodes, all we need to do is override the specific visit method for the right node type and then append more items to our ranges array.
That simple visitor is already capable of collecting the information needed for the editor to fold all class and method definitions—regardless of what the file structure looks like. This is the Ruby LSP’s preferred strategy for implementing nonpositional requests.
Currently Supported Features
The most up to date information about supported features can be found in the Ruby LSP’s documentation. At the time of this writing, the supported features from the specification are:
Code Actions
- Fixes violations with RuboCop quickfixes
- Refactors action to extract a piece of code into a variable
Diagnostics
- Shows RuboCop violations on the editor
Document Highlight
- Highlights all occurrences of the same entity under the cursor position
Document Link
- Jumps to a gem’s source code through magic source comments
Document Symbol
- Populates the editor’s outline and breadcrumbs with all available Ruby structures
- Allows fuzzy searching structures (VS Code hotkey: CMD + SHIFT + O)
Folding Range
- Determines where Ruby code can be folded and expanded
Formatting
- Fixes RuboCop violations on save
- SyntaxTree formatting is also supported for applications not using RuboCop
Hover
- Displays documentation for Rails DSL methods when hovering with the cursor
Inlay Hints
- Displays the default behavior on rescue when an error class is not specified
On Type Formatting
- Autocompletes end tokens while typing
- Autocompletes string interpolation braces and block argument pipes
- Continues comments on the next line automatically
Selection Ranges (Smart Ranges)
- Allows expanding or narrowing a selection based on the structure of the code (VS Code hotkey: CTRL + SHIFT + LEFT/RIGHT ARROW)
Semantic highlighting
- Highlights code consistently based on how Ruby understands it
Completion
- When writing a require, the editor autocompletes possible paths after inserting the first forward slash
YJIT and YARP
Because language servers have such a critical performance requirement, many of them are written in programming languages other than the one the server is made for. For example, the Python (pylance) language server is written in TypeScript and Sorbet is written in C++. However, the Ruby LSP isn’t one of those cases and is completely written in pure Ruby.
This approach has advantages: we can quickly iterate on features thanks to Ruby’s ease of use, we can use Ruby’s own parser (Ripper) through the Syntax Tree gem to analyze files and we have access to the complete Ruby environment the application runs on. On the other hand, performance is a constant concern as parsing and analyzing Ruby files are expensive operations.
For these reasons, recent Ruby developments focused on performance such as YJIT, object shapes and variable width allocation are extremely beneficial to the Ruby LSP, allowing it to achieve its performance goals. If you’re using the Ruby LSP VS Code extension and Ruby 3.2 compiled with YJIT, the Ruby LSP will default to using YJIT for a significant performance boost.
Another upcoming development of great interest for the Ruby LSP is YARP (Yet Another Ruby Parser). This project being built at Shopify aims to create a new Ruby parser to replace the existing one with two major features that are currently missing: portability and error tolerance. This is critical for modern tooling for two reasons:
- Being portable means that it can be integrated with different programming languages. This opens the door to creating performant tooling based on whatever language is right for the job.
- While a developer is in the middle of a coding session, the code is rarely in a complete state. Most of what language servers see are temporary syntax errors until the user finishes typing. Using an error tolerant parser means that the language server can continue to provide features properly even in the presence of syntax errors, while at the same time informing users of what the errors are and how to correct them.
How can I use it?
Disclaimer: this section only includes instructions for VS Code, but the Ruby LSP can be used with any other editor that supports LSPs!
The most up to date information can always be found in the Ruby LSP extension documentation. To set up the Ruby LSP in VS Code:
- Install the extension from the marketplace or from inside VS Code itself.
- If using a Ruby version manager, such as rbenv, configure the extension to use it.
- Add the ruby-lsp gem to your project’s bundle.
- Done! Status information and configuration can be found in the language status item, right before the language mode “Ruby”.
Future Plans
To achieve adequate performance on large files and codebases, making editor interactions feel responsive, and to reach the level of feature completeness we desire, including Rails, GraphQL and other tool specific functionality, there are three themes that must be addressed in the future.
Parallelism
Meeting language servers performance requirements without parallelism is difficult. The more features are added, the more requests are sent to the server in large batches. The main bottleneck is if the server falls behind in processing the queue, which translates to lag in the editor.
When the Ruby LSP implements a larger portion of the specification, there’s a good chance that adopting parallelism will become necessary. Since requests are mostly independent, being able to run more than one at the same time makes a big difference in keeping up with the quickly growing request queue.
Codebase Indexing
Various features in the LSP specification require knowledge of the codebase being worked on. A common example is Go to Definition: the server needs to know where the definition of every method and constant is to know where to jump to.
Hover (displaying information about a method or constant when hovering over it with the cursor), Signature Help (displaying method signatures when invoking them) and Workspace Symbols (fuzzy searching for constants or methods across the entire codebase) are other features unlocked by building a knowledge of the codebase.
To provide these features, the Ruby LSP will need to build and maintain an index of the codebase, including every constant and method defined in that project’s files. This will involve building the initial index, synchronizing the index if a file is added, removed or modified and possibly using a caching mechanism to avoid rebuilding the index from scratch every time the LSP is activated.
Plugins
Providing functionality that is specific to a particular tool or framework is beneficial for developers. Taking Rails applications as an example, the Ruby LSP could provide hot reload on saving files, allow jumping between controller action and its corresponding route and showing column information when hovering over a model.
Despite being a considerable developer productivity boost, it wouldn’t be scalable to maintain this type of specific functionality for every tool or framework inside the Ruby LSP’s primary codebase. It would not only overcomplicate the codebase, but also become a bottleneck for tools that want to deliver tailored experiences in editors since all of the code would have to go through the same repository. Additionally, since different projects use different tools, it makes sense to have a degree of separation between default and addon behavior.
To aggregate this functionality in the Ruby LSP in a scalable way, while at the same time giving the maintainers of tools and frameworks complete freedom to provide editor features, we will need to design a plugin system for the server.
In its final state, the system would allow tools to export plugins from their own codebases, which are then loaded by the Ruby LSP to enhance existing features with tool specific functionality—similar to Rack middleware. In the case of our previous example, imagine a plugin exported from Rails to provide editor features related to the framework.
Closing Thoughts
Improving the experience of coding in Ruby is highly aligned with its goal of making the developer happy—and the future of Ruby tooling is exciting. We hope that you’ll give the Ruby LSP a try and that it brings you joy while coding. Let us know if you have feedback or if you encounter issues in our repository. And if you’d like more Ruby LSP related content, be sure to check out this RubyConf 2022 talk.
Vinicius Stock is a Senior Developer on Shopify’s Ruby Developer Experience team, and the lead of the Ruby LSP project. You can find him on Twitter or GitHub as @vinistock.
Open source software plays a vital and integral part at Shopify. If being a part of an Engineering organization that’s committed to the support and stewardship of open source software sounds exciting to you, visit our Engineering career page to find out about our open positions and learn about Digital by Design.