


By Ashay Pathak and Selina Li
Tens of thousands of merchants use Shopify Inbox as a single business chat app for all online customer interactions and staff communications. Over four million conversations were exchanged on Shopify Inbox in 2020, and 70 percent of Shopify Inbox conversations are with customers making a purchasing decision. This prompted the Shopify Data team to ask ourselves, “How can we help merchants identify and convert those conversations to sales?”
We built a real-time buyer signal data pipeline to surface relevant customer context—including active cart activities and order completion information—to merchants while they’re chatting with their customers. With these real-time, high-intent customer signals, merchants know where the buyers are in their shopping journey—from browsing products on online stores to placing orders. Merchants can ask more direct questions, better answer customer inquiries, and prioritize conversations that are more likely to convert.

We’ll share how we designed our pipeline, along with how we uncovered insights on merchant behaviors through A/B testing. We’ll also discuss how we address the common problems of streaming solutions, tackle complex use cases by leveraging various Apache Beam functions and measure success using an experiment.
Overview
Buyers can message merchants from many different channels like Online Store Chat, Facebook Messenger, and Apple Business Chat. Shopify Inbox allows merchants to manage customer conversations from different messaging channels within a single business chat app. While it’s a great tool for managing customer conversations, we wanted to go one step further by helping merchants optimize sales opportunities on existing conversations and prioritize conversations as they grow.
The majority of Shopify Inbox conversations are with customers making a purchasing decision. We need to identify signals that represent buyers’ purchase intent and surface it at the right time during a conversation. How we achieve this is by building a real-time Apache Beam pipeline that surfaces high-intent buyer signals in Shopify Inbox.
When a buyer has an active conversation with a merchant, we currently share two buyer signals with the merchant:
- Cart action event: Provides information on buyers’ actions on the cart, product details, and the current status of the cart.
- Order completion event: Provides information on the recent purchase a buyer has made, including an order number URL that enables merchants to view order details in the Shopify admin (where merchants login to manage their business).
These signals are shared in the form of conversation events (as shown in the below image). Conversation events are the means for communicating context or buyer behavior to merchants that are relevant during the time of the conversation. They’re inserted in chronological order within the message flow of the conversation without adding extensive cognitive loads to merchants.

In general, the cart and order completion events are aggregated and shared based on the following characteristics:
- Pre-conversation events: Events that happen up to 14 days before a conversation is initiated.
- Post-conversation events: Events that happen after a conversation is initiated. The conversation has a life cycle of seven days, and we maintain events in state until the conversation expires.
Architecture
To deliver quality information to merchants on time, there are two main requirements our system needs to fulfill: low latency and high reliability. We do so by leveraging three key technologies:
- Apache Kafka
- Apache Beam
- Google Cloud Dataflow

Message Queues with Apache Kafka
For this pipeline we use two different forms of Kafka events: Monorail and Change Data Capture.
Monorail
Monorail is an abstraction layer developed internally at Shopify that adds structure to the raw Kafka events before producing it to Kafka. Also with the structure there’s support for versioning, meaning that if the schema produces upstream changes, then it gets produced to the updated version while the Kafka topic remains the same. Having version control is useful in our case as it helps to ensure data integrity.
Change Data Capture(CDC)
CDC uses binlogs and Debezium to create a stream of events from changed data in MySQL databases and supports large record delivery. Some of the inputs to our pipeline aren’t streams by nature, so CDC allows us to read such data by converting it to a stream of events.
Real-time Streaming Processing with Apache Beam
Apache Beam is a unified batch and stream processing system. Instead of using a batch system to aggregate months of old data and a separate streaming system to process the live user traffic, Apache Beam keeps these workflows together in one system. For our specific use case where the nature of events is transactional, it’s important for the system to be robust and handle all behaviors in a way that the results are always accurate. To make this possible, Apache Beam provides support with a variety of features like windowing, timers, and stateful processing.
Google Cloud Dataflow for Deploying Pipeline
We choose to use Google Dataflow as a runner for our Apache Beam model. Using a managed service helps us concentrate on the logical composition of our data processing job without worrying too much about physical orchestration of parallel processing.
High Level System Design

The pipeline ingests data from CDC and Monorail while the sink only writes to a Monorail topic. We use Monorail as the standardized communication tool between the data pipeline and dependent service. The downstream consumer processes Monorail events that are produced from our model, structuring those events and sending them to merchants in Shopify Inbox.
The real-time buyer signals pipeline includes the following two main components:
- Events Filtering Jobs: The cart and checkout data are transactional and include snapshots on every buyer interactions on cart and checkout. Even during non-peak hours, there are tens of thousands of events we read from the cart and checkout source every second. To reduce the workloads of the pipeline and optimize resources, this job only keeps mission-critical events (that is, only relevant transactional events of Shopify Inbox users).
- Customer Events Aggregation Job: This job hosts the heavy lifting logic for our data pipeline. It maintains the latest snapshot of a buyer’s activities in an online store, including the most recent conversations, completed orders, and latest actions with carts. To make sure this information is accessible at any point of time, we rely on stateful processing with Timers and Global Window in Apache Beam. The event-emitting rule is triggered when a buyer starts a conversation.
The customer events aggregation job is the core of our real-time pipeline, so let’s dive into the design of this job.
Customer Events Aggregation Job

As shown on the diagram above, we ingest three different input collections, including filtered conversation, checkout and cart events in the customer events aggregation job. All the input elements are keyed by the unique identifier of a buyer on an online store using the CoGroupByKey operator _shopify_y (see our policy on what information Shopify collects from visitors’ device). This allows us to group all input elements into a single Tuple collection for easier downstream processing. To ensure we have access to historical information, we leverage the state in Apache Beam that stores values by per-key-and-window to access last seen events. As states expire when a window ends, we maintain the key over a Global Window that’s unbonded and contains a single window to allow access to states at any time. We maintain three separate states for each customer event stream: conversation, checkout, and cart state. Upon arrival of new events, a processing time trigger is used to emit the current data of a window as a pane. Next, we process last seen events from state and new events from pane through defined logics in PTransform.
In this stage of the system, upon receiving new events from a buyer, we try to answer the following questions:
1. Does this buyer have an active conversation with the merchant?
This question determines whether our pipeline should emit any output or should just process the cart/checkout events and then store them to its corresponding state. The business logic of our pipeline is to emit events only when the buyer has started a conversation with the merchant through Shopify Inbox.
2. Do these events occur before or after a conversation is started?
This question relates to how we aggregate the incoming events. We aggregate events based on the two characteristics we mentioned above:
- Pre-conversation events:We show transactional data on buyers’ activities that occur after a conversation is initiated. Using the same scenario mentioned above, we show a cart addition event and an order completion event to the merchant.
- Post-conversation events: We show transactional data on buyers’ activities that occur after a conversation is initiated. Using the same scenario mentioned above, we show a cart addition event and an order completion event to the merchant.
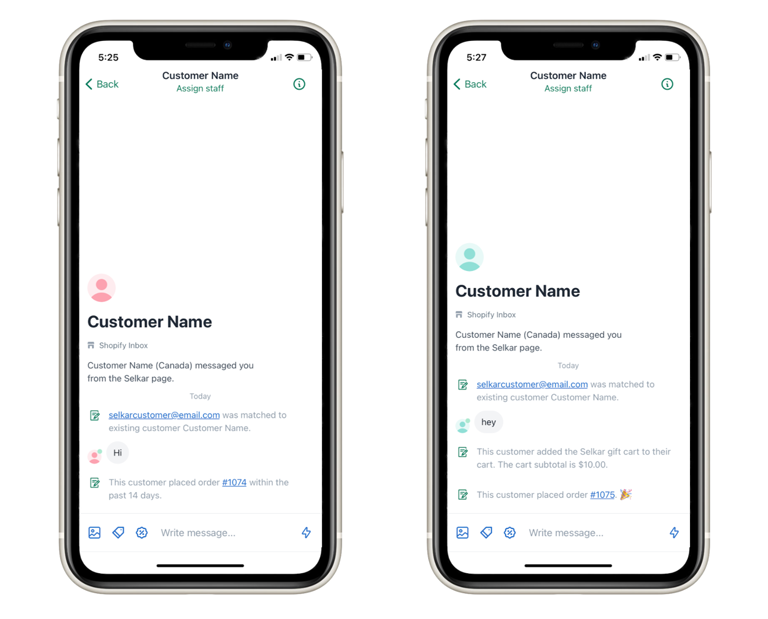
3. What is the latest interaction of a buyer on an online store?
This question reflects the key design principle of our pipeline—the information we share with merchants should be up-to-date and always relevant to a conversation. Due to the nature of how streaming data arrives at a pipeline and the interconnected process between cart and checkout, it introduces the main problems we need to resolve in our system.
There are a few challenges we faced when designing the pipeline and its solutions.
Interdependency of Cart and Checkout
Cart to checkout is a closely connected process in a buyer’s shopping journey. For example, when a buyer places an order and returns to the online store, the cart should be empty. The primary goal of this job is to mock this process in the system to ensure correct reflection on cart checkout status at any time. The challenge is that cart and checkout events are from different Monorail sources but they have dependencies on each other. By using a single PTransform function, it allows us to access all mutable states and create dynamic logic based on that. An example of this is that we clear the cart state when receiving a checkout event of the same user token.
Handling Out-of-Order Events
As the information we share in the event is accumulative (for example, total cart value) sharing the buyer signal events in the correct sequence is critical to a positive merchant experience. The output event order should be based on the chronological order of the occurrence of buyers’ interaction with the cart and chat. For example, removal of an item should always come after an item addition. However, one of the common problems with streaming data is we can’t guarantee events across data sources are read and processed in order. On top of that, the action on the cart isn’t explicitly stated in the source. Therefore, we rely on comparing quantities change between transactional events to extract the cart action.
This problem can be solved by leveraging stateful processing in Apache Beam. A state is a buffer that stores values by per-key-and-window. It’s mutable and evolved with time and new incoming elements. With the use of state, it allows us to access previous buyer activity snapshots and identify any out-of-order events by comparing the event timestamp between new events and events from the state. This ensures no outdated information is shared with merchants.
Garbage Collection
To ensure we’re not overloading data to states, we use Timer to manually clean up the expired or irrelevant per-key-and-window values in states. The timer is set to use the event_time domain to manage the state lifecycle per-key-and-window. We use this to accommodate the extendable lifespan of a cart.
Sharing Buyer Context Across Conversations
Conversations and cart cookies have different life spans. The problem we had was that the characteristics of events can be evolved across time. For example, a post-conversation cart event can be shared as a pre-conversation event upon the expiration of a conversation. To address this, we introduced a dynamic tag in states to indicate whether the events have been shared in a conversation. Whenever the timer for the conversation state executes, it will reset this tag in the cart and checkout state.
Testing Our Pipeline
Through this real-time system, we expect the conversation experience to be better for our merchants by providing them these intelligent insights about the buyer journey. We carried out an experiment and measured the impact on our KPI’s to validate the hypothesis. The experiment had a conventional A/B test setup where we divided the total audience (merchants using Shopify Inbox) into two equal groups: control and treatment. Merchants in the control group continued to have the old behavior, while the treatment group merchant saw the real-time buyer signal events in their Shopify Inbox client app. We tracked the merchant experience using the following metrics:
- Response Rate: Percent of buyer conversations that got merchant replies. We observed a significant increase of two percent points.
- Response Time: Time between first buyer message and first merchant response. While we saw the response rate significantly increase, we observed no significant change in response time, signifying that merchants are showing intent to reply quicker.
- Conversion Rate: Percent of buyer conversations that got attributed to a sale. We observed a significant increase of 0.7 percent points.
Our experiments showed that with these new buyer signals being shown to merchants in real-time, they’re able to better answer customer queries because they know where the buyers are in their shopping journey. Even better, they’re able to prioritize the conversations by responding to the buyer who is already in the checkout process, helping buyers to convert quicker. Overall, we observed a positive impact on all the above metrics.
Key Takeaways of Building Real-time Buyer Signals Pipeline
Building a real-time buyer signal data pipeline to surface relevant customer context was a challenging process, but one that makes a real impact on our merchants. To quickly summarize the key takeaways:
- Apache Beam is a useful system for transactional use cases like cart as it provides useful functionalities such as state management and timers.
- Handling out of order events is very important for such use cases and to do that a robust state management is required.
- Controlled experiments are an effective approach to measure the true impact of major feature changes and derive valuable insights on users' behaviors.
Ashay Pathak is a Data Scientist working on Shopify’s Messaging team. He is currently working on building intelligence in conversations & improving chat experience for merchants. Previously he worked for an intelligent product which delivered proactive marketing recommendations to merchants using ML. Connect with Ashay on Linkedln to chat.
Selina Li is a Data Scientist on the Messaging team. She is currently working to build intelligence in conversation and improve merchant experiences in chat. Previously, she was with the Self Help team where she contributed to deliver better search experiences for users in Shopify Help Center and Concierge. Check out her last blog post on Building Smarter Search Products: 3 Steps for Evaluating Search Algorithms. If you would like to connect with Selina, reach out on Linkedin.
Interested in tackling challenging problems that make a difference? Visit our Data Science & Engineering career page to browse our open positions.