


Five years ago, my team and I launched the first machine learning product at Shopify. We were determined to build an algorithm-powered product that solved a merchant problem and made a real impact on the business. Figuring out where to start was the hardest part. There was (and still is!) a lot of noise out there on best practices.
Fast forward to today, and machine learning is threaded into many aspects of Shopify. How did we get to this point? Through our experience building our first few models, we carved out a pragmatic step-by-step guide that has enabled us to successfully scale machine learning across our organization.
Our playbook is tech-independent and can be applied in any domain, no matter what point you’re at in your machine learning journey—which is why we’re sharing it with you today.
Starting From Zero
The first few problems your team chooses to solve with machine learning have a disproportionate impact on the success and growth of your machine learning portfolio. But knowing which problem to start with can be difficult.
1. Identify A Problem Worth Solving
You want to pick a problem that your users care about. This will ensure your users use your solution day in and day out and enable you to gather feedback quickly. Having a deep understanding of your problem domain will help you achieve this. Nothing surpasses the ability to grasp your business goals and user needs. This context will guide your team on what your product is trying to achieve and what data-driven solutions will have a real impact on these priorities.
One way Shopify achieves this is by embedding our data scientists into our various product and commercial lines. This ensures that they have their finger on the pulse and are partners in decision making. With this domain context, we were able to identify a worthy first problem—order fraud detection. Sales are the main goal of our merchants, so we knew this problem impacted every merchant. We also knew the existing solution was a pain point for them (more on this later).

2. Ensure You Have Enough Data
Good, accessible data is half the battle for building a successful model. Many organizations collect data, but you need to have a high degree of confidence in it, otherwise, you have to start collecting it anew. And it needs to be accessible. Is your data loaded into a medium that your data scientists can use? Or do you have to call someone in operations to move data from an S3 bucket?
In our case, we had access to 10 years of transaction data that could help us understand the best inputs and outputs for detecting fraudulent orders. We have an in-house data platform and our data scientists have easy access to data through tools like Trino (formerly Presto). But the technology doesn’t matter, all that matters is that whatever problem you choose, you have trustworthy and accessible data to help you understand the problem you’re trying to solve.
3. Identify Your Model’s Downstream Dependencies
Keep in mind that any problem you pick won’t be an abstract, isolated problem—there are going to be things downstream that are impacted by it. Understanding your user’s workflow is important as it should influence the conditions of your target.
For example, in order fraud, we know that fulfillment is a downstream dependency. A merchant won’t want to fulfill an order if it’s a high risk of fraud. With this dependency in mind, we realized that we needed to detect fraud before an order is fulfilled: after would leave our prediction useless.
4. Understand Any Existing Solutions
If the problem you’re trying to solve has an existing solution, dig into the code and data, talk to the domain experts and fully understand how that solution is performing. If you’re going to add machine learning, you need to identify what you’re trying to improve. By understanding the existing solution, you’ll be able to identify benchmarks for your new solution, or decide if adding machine learning is even needed.
When we dug into the existing rule-based solution for detecting order fraud, we uncovered that it had a high false positive rate. For example, if the billing and shipping address on an order differed, our system would flag that order. Every time an order was flagged our merchants had to investigate and approve it, which ate up precious time they could be spending focused on growing their business. We also noticed that the high false positive rate was causing our merchants to cancel good orders. Lowering the false positive became a tangible benchmark for our new solution.
5. Optimize For Product Outcomes
Remember, this is not an exercise in data science—your product is going to be used by real people. While it’s tempting to optimize for scores such as accuracy, precision and recall, if those scores don’t improve your user experience, is your model actually solving your problem?

For us, helping merchants be successful (i.e. make valid sales) was our guiding principle, which influenced how we optimize our models and where we put our thresholds. If we optimized our model to ensure zero fraud, then our algorithm would simply flag every order. While our merchants would sell nothing, we would achieve our result of zero fraud. Obviously this isn’t an ideal experience for our merchants. So, for our model, we optimized for helping merchants get the highest number of valid sales.
While you might not pick the same problem, or have the same technology, by focusing on these steps you’ll be able to identify where to add machine learning in a way that drives impact. For more tips from Shopify on building a machine learning model, checkout this blog.
Zero to One
So you’ve built a model, but now you’re wondering how to bring it to production? Understanding that the strength of everything that data science builds is on the foundation of a strong platform will help you find your answer. In order to bring your models to production in a way that can scale, you simply need to begin investing in good data engineering practices.
1. Create Well-Defined Pipelines
In order to confidently bring your model to production, you need to build well-defined pipelines for all stages of predictive modeling. For your training pipeline, you don’t want to waste time trying to keep track of your data and asking, “Did I replace the nulls with zeros? Did my colleagues do the same?” If you don’t trust your training, you’ll never get to the point where you feel comfortable putting your model into production. In our case, we created a clean pipeline by clearly labeling our input data, transformations and the features that go into our model.
You’ll want to do the same with your verification and testing pipeline. Building a pipeline that captures rich metadata around which model or dataset was used in your training will enable you to reproduce metrics and trace bugs. With these good data engineering practices in place, you’ll remove burdensome work and be able to establish model trust with your stakeholders.
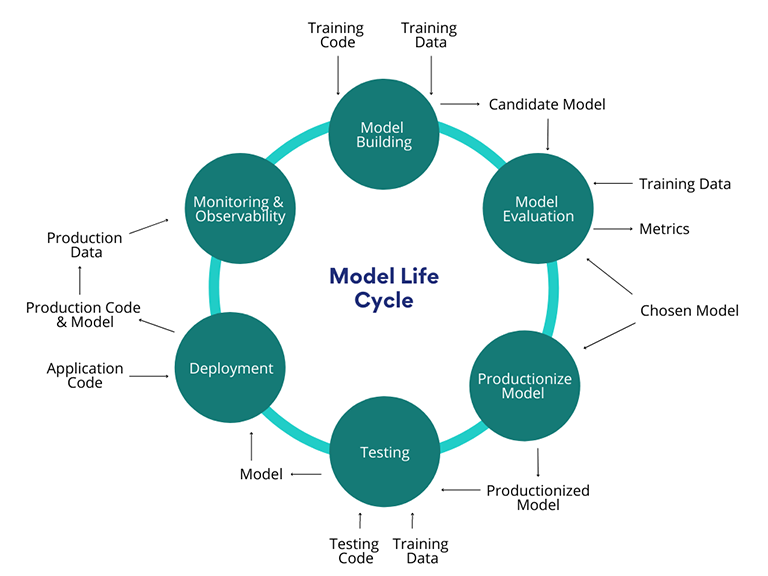
2. Decide How to Deploy Your Model
There are a lot of opinions on this, but the answer really depends on the problem and product context. Regardless of which decision you make, there are two key things to consider:
- What volume will your model experience? Is your model going to run for every user? Or only a select group? Planning for volume means you’ll make better choices. In our case, we knew that our deployment choice had to be able to deal with varying order volumes, from normal traffic days to peak sales moments like Black Friday. That consideration influenced us to deploy the model on Shopify’s core tech stack—Ruby on Rails—because those services are used to high-volume and have resources dedicated to keeping them up and running.
- What is the commitment between the user and the product? Understand what the user expects or what the product needs because these will have implications on what you can build. For example, our checkout is the heartbeat of our platform and our merchants expect it to be fast. In order to detect fraud as soon as an order is made, our system would have to do a real-time evaluation. If we built an amazing model, but it slowed down our checkout, we would solve one problem, but cause another. You want to limit any unnecessary product or user strain.
By focusing on these steps, we were able to quickly move our order fraud detection model into production and demonstrate if it actually worked—and it did! Our model beat the baseline, which is all we could have asked for. What we shipped was a very simple logistic regression model, but that simplicity allowed us to ship quickly and show impact. Today, the product runs on millions of orders a day and scales with the volume of Shopify.
Our first model became the stepping stone that enabled us to implement more models. Once your team has one successful solution in production, you now have an example that will evangelize machine learning within your organization. Now it’s time to scale.
One to One Hundred
Now that you have your first model in production, how do you go from one model to multiple models? Whether that’s in the same product or bringing machine learning to other existing products? You have to think about how you can speed up and scale your model building workflows.
1. Build Trust In Your Models
While deploying your first model you focused on beginning to build good engineering practices. As you look to bring models to new products, you need to solidify those practices and build trust in your models. After we shipped our order fraud detection model, we implemented the following key processes into our model lifecycle to ensure our models are trustworthy, and would remain trustworthy:
- Input and output reconciliation: Ensure the data sets that you use during training match the definition and the measurements of what you see at the time of inference. You’ll also want to reconcile the outcomes of the model to make sure that for the same data you’re predicting the same thing. It seems basic, but we’ve found a lot of bugs this way.
- Production backtesting: Run your model in shadow for a cohort of users, as if it’s going to power a real user experience. Running backtests for our order fraud detection model allowed us to observe our model predictions, and helped us learn the intricacies of how what we’d built functioned with real world data. It also gave us a deployment mechanism for comparing models.
- Monitoring: Conditions that once made a feature true, may change over time. As your models become more complex, keeping on top of these changes becomes difficult. For example, early on in Shopify’s history, mobile transactions were highly correlated with fraud. However, we passed a tipping point in ecommerce where mobile orders became the primary way of shopping, making our correlation no longer true. You have to make sure that as the world changes, as features change, or distributions change, there's either systems or humans in place to monitor these
2. Encode Best Practices In Your Platform
Now that you’ve solidified some best practices, how do you scale that as your team grows? When your team is small and you only have 10 data scientists, it’s relatively straightforward to communicate standards. You may have a Slack channel or a Google Doc. But as both your machine learning portfolio and team grow, you need something more unifying. Something that scales with you.
A good platform isn’t just a technology enabler—it’s also a tool you can use to encode culture and best practices. That’s what we did at Shopify. For example, as we outlined above, backtesting is an important part of our training pipeline. We’ve encoded that into our platform by ensuring that if a model isn’t backtested before it goes into production, our platform will fail that model.
While encoding best practices will help you scale, it’s important that you don’t abstract too early. We took the best practices we developed while deploying our order fraud protection model, and a few other models implemented in other products, and we conducted trial and error. Only after taking a few years to see what worked, did we encode these practices into our platform.
3. Automate Things!
If on top of building the foundations, our team had to monitor, version, and deploy our models every single day, we’d still be tinkering with our very first model. Ask yourself, “How can I scale far beyond the hours I invest?” and begin thinking in terms of model operations—scheduling runs, automatic checks, model versioning, and, one day, automatic model deployment. In our case, we took the time to build all of this into our infrastructure. It all runs on a schedule every day, every week, for every merchant. Of course, we still have humans in the loop to dig into any anomalies that are flagged. By automating the more operational aspects of machine learning, you’ll free up your data scientists’ time, empowering them to focus on building more awesome models.

These last three steps have enabled us to deploy and retrain models fast. While we started with one model that sought to detect order fraud, we were able to apply our learnings to build various other models for products like Shopify Capital, product categorization, the Shopify Help Center search, and hundreds more products. If you’re looking to go from one to one hundred, follow these steps, wash, rinse and repeat and you’ll have no problem scaling.
This Is a Full-Stack Problem
Now you have a playbook to scale machine learning in your organization. And that’s where you want to end up—in a place where you’re delivering more value for the business. But even with all of these steps, you won’t truly be able to scale unless your data scientists and data engineers work together. Building data products is a full-stack problem. Regardless of your organization structure, data scientists and data engineers are instrumental to the success of your machine learning portfolio. As my last piece of wisdom, ensure your data scientists and data engineers work in alignment, off of the same road map, and towards the same goal. Here’s to making products smarter for our users!
Solmaz is the Head of Commerce Intelligence and VP of Data Science and Engineering at Shopify. In her role, Solmaz oversees Data, Engineering, and Product teams responsible for leveraging data and artificial intelligence to reduce the complexities of commerce for millions of businesses worldwide.
If you’re passionate about solving complex problems at scale, and you’re eager to learn more, we're hiring! Reach out to us or apply on our careers page.