


In 2022, we shipped Merlin, Shopify’s new and improved machine learning platform built on Ray. We built a flexible platform to support the varying requirements, inputs, data types, dependencies and integrations we deal with at Shopify (you can read all about Merlin’s architecture in our previous blog). Since then, we’ve enhanced the platform by onboarding more use cases and adding features to complete the end-to-end machine learning workflow, including:
- Merlin Online Inference, which provides the ability to deploy and serve machine learning models for real-time predictions.
- Model Registry and experiment tracking with Comet ML.
- Merlin Pipelines, a framework for reproducible machine learning pipelines on top of Merlin.
- Pano Feature Store, an offline / online feature store built on top of an open source feature store, Feast.
The ability to provide real-time predictions for user-facing applications and services is an important requirement at Shopify, and will become increasingly critical as more machine learning models are integrated closer to user-facing products. But it’s a challenging requirement. As machine learning is utilized by many different teams across Shopify, each with its own use-cases and requirements, we had to ensure that Merlin’s online inference could be an effective, generalized solution. We needed to build something robust that could be used by all of our use-cases and allow low-latency, while serving machine learning models at Shopify scale.
In this blog post, we’ll walk through how we built Merlin’s online inference capabilities to deploy and serve machine learning models for real-time prediction at scale. We’ll cover everything from the serving layer where our users can focus solely on their specific inference logic, to service deployment where we utilized our internal service ecosystem to ensure that online inference services can scale to Shopify’s capabilities.
What is online inference?
In machine learning workflows, once a model has been trained, evaluated and productionized, it can be applied on input data to return predictions. This is called machine learning inference. There are two main types of inference, batch and online inference.
While batch inference can run periodically on a finite set of data, online inference is the ability to compute predictions in real-time as the input becomes available. With online inference, the observations that we produce predictions for can be infinite, as we’re using streams of data that are generated over time.
Popular examples for online inference and real-time predictions can be found in many use cases. Some examples are recommender systems, where having real-time predictions can provide users with the most relevant results, or fraud detection, where the ability to detect fraud is required as soon as it happens. Other Shopify specific use cases that benefit from online inference are product categorization and inbox classification.
When serving machine learning models for real time predictions, latency becomes much more important compared to batch jobs, as the latency of machine learning models can impact the performance of user facing services and impact the business. When considering online inference for a machine learning use case, it is important to consider:
- The cost
- The use-case requirements
- The skillset of the team members (e.g. being able to handle running and maintaining machine learning services in production versus running them in batch jobs).
As we prepared to expand Merlin for online inference, we first interviewed our internal stakeholders to better understand their use-case requirements more in detail. Once we had these, we could design the system, its architecture and infrastructure in ways that optimize for cost and performance, as well as advise the machine learning teams on staffing and required support, based on the service-level objectives of their use-case.
Online Inference with Merlin
There are several requirements that we set out to provide with Merlin Online Inference:
- Robust and flexible serving of machine learning models, to enable us to serve and deploy different models and machine learning libraries used at Shopify (e.g. TensorFlow, PyTorch, XGBoost).
- Low latency, in order to optimize processing of an inference request to provide responses with minimal delay.
- State-of-the-art features for online inference services, like rolling deployments, autoscaling, observability, automatic model updates, etc.
- Integration with the Merlin machine learning platform, so users can utilize the different Merlin features, such as model registry and Pano online feature store.
- Seamless and streamlined service creation, management and deployment for machine learning models.
With these requirements in mind, we aimed to build Merlin Online Inference to enable deploying and serving machine learning models for real-time predictions.
Merlin Online Inference Architecture
In our previous Merlin blog post, we described how Merlin is used for training machine learning models. With Merlin Online Inference, we can provide our data scientists and machine learning engineers with the tools to deploy and serve their machine learning models and use cases.
Every machine learning use case that requires online inference runs as its own dedicated service. These services are deployed on Shopify’s Kubernetes clusters (Google Kubernetes Engine) as any other Shopify service. Each service lives in its own Kubernetes namespace and can be configured individually, for example, to autoscale based on different parameters and metrics.

Each service loads its dedicated machine learning model from our model registry, Comet ML, as well as any other required artifacts. Different clients can call an inference endpoint to generate predictions in real-time. The main clients that use Merlin Online Inference services are Shopify’s core services (or any other internal service that requires real-time inference), as well as streaming pipelines on Flink for near real-time predictions. Pano, our feature store, can be used to access features in low latency during inference both from the Merlin Online Inference service or from the different clients that send requests to the service.
Each service has a monitoring dashboard with predefined metrics such as latency, requests per second, CPU, etc. This can be used to observe the health of the service, and can be further customized per service.
Each Merlin Online Inference service has two main components:
- Serving layer: the API that enables an endpoint to return predictions from a model.
- Deployment: how the service will be deployed in Shopify’s infrastructure.
Serving Layer
The Merlin Online Inference serving layer is the API that serves the model (or models). It exposes an endpoint for processing inputs from the clients, and returns predictions from the model. The serving layer accomplishes the following:
- Starts a web server for the service
- Loads the model and additional artifacts to memory as part of the initialization process
- Exposes an endpoint for the inference function that will take features as inputs and return predictions
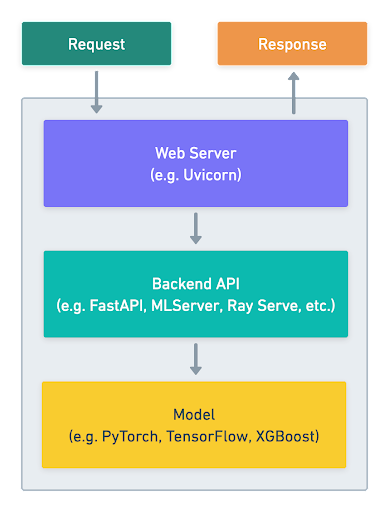
The serving layer is written in Python, which makes it easier for our data scientists and machine learning engineers to implement it. It’s defined in the Merlin Project of each use case. A Merlin Project is a folder in our Merlin mono-repo where the code, configuration and tests of the use case are kept. This allows the serving layer to reuse different parts of the machine learning workflow logic. The serving layer is added to the Merlin Docker image, which is created by Podman from a dedicated Dockerfile. It is then deployed in the Merlin Online Inference Kubernetes clusters.
Serving Layer Types
When analyzing the requirements of our users, we identified a need to support multiple types of serving layers. We wanted to make sure that we can abstract from our users a lot of the hassle of writing a complete API for every machine learning use case, while also enabling other more custom services.
In order to do that, we currently support two types of serving libraries with Merlin Online Inference:
- MLServer: An open source inference server for machine learning models built by Seldon. MLServer supports REST and gRPC interfaces out of the box as well the ability to batch requests. It supports the V2 inference protocol that standardizes communication protocols around with different inference servers and by that increases their utility and portability.
- FastAPI: A fast and high-performance web framework for building APIs with Python.
These two libraries enable three different methods for our users to implement their online inference serving layer, starting from no code or low code with MLServer, to a fully customizable API using FastAPI. The following table describes the differences between these approaches:
| Serving Layer Type | Description | What to Use |
| No Code |
Uses MLServer’s pre-built inference serving implementations. Only requires configuration changes in MLServer json files. |
For this serving layer type, you have a model and all you need is to deploy it behind an end point such as Scikit-learn, XGBoost, LightGBM, ect. |
| Low Code |
Uses MLServer’s custom serving implementation. Requires minimal code implementation of the serving class. |
Include transformation or business logic in the serving layer, or a model that uses an unsupported ML library in MLServer. |
| Full Custom | In this case, the user gets pre-defined boilerplate code for a FastAPI serving layer which they can fully customize. | The machine learning use case needs to expose additional endpoints or a requirement that is unsupported in MLServer. |
Creating the Serving Layer in Merlin
In order to abstract away much of the complexity of starting to write a serving layer from scratch, we wrote Merlin CLI, which uses input from the user to build a custom serving layer. This serving layer will be generated from a predefined cookiecutter, and will provide boilerplate code for the user to build on.

In the image above, the user can choose the inference library that they want to implement their serving layer in, then pick the machine learning library that they will use to load and serve their model.
Example of Serving a Custom Model with MLServer
Once we’ve created the boilerplate code for the serving layer, we can start implementing the specific logic for our use-case. In the following example, we’re serving a 🤗Hugging Face 🤗 model to translate English to French with online inference.
We create a class for our model which inherits from mlserver.MLModel and implements the following methods:
- Load: loads the model and any additional required artifact to memory.
- Predict: generates predictions from the model based on a payload that the method received.
In addition, with MLServer, there’s an option to serve models as a pre-built HuggingFace runtime using only configuration files:
The above is a very basic example of how low code and no-code examples can be used with MLServer without the need to define the whole API from scratch. This allows our users to focus only on what matters most to them, which is loading the model and serving it to generate inference.
Testing the Serving Layer with Merlin Workspaces
For testing purposes, our users can take advantage of the tools we already have in Merlin. They can create Merlin Workspaces, which are dedicated environments that can be defined by code, dependencies and required resources. These dedicated environments also enable distributed computing and scalability for the machine learning tasks that run on them. They are intended to be short lived, and our users can create them, run the serving layer in them, and expose a temporary endpoint for development, debugging and stress testing. This enables fast iterations on the serving layer, as it abstracts the friction of deploying a complete service between each iteration.

In the diagram above, we can see how different use cases run with their respective Merlin Workspaces on Merlin. Each use case can define their own infrastructure resources, machine learning libraries, Python packages, serving layer, etc. and run them in an isolated and scalable environment. This is where our users can iterate on their use cases while developing their model and serving layer, in the same way that they would for any other part of their machine learning workflow.
The Merlin Workspace enables our users to access the swagger page of their API. This enables them to test out their code and make sure that it works before deploying it as a service.
Merlin Online Inference Service Deployment
Once the serving layer has been tested and validated, it’s ready to be deployed to production as a service. The deployment phase is where all of the Merlin components will be put together to form the deployed service. These components include the serving layer code, API, model, artifacts, libraries and requirements, image container that was created in the CI/CD pipelines and any additional configuration libraries and package requirements to form the Merlin Service.

Creating a Merlin Service
Similarly to the serving layer creation, we leverage the same Merlin CLI to create a Merlin Service in Shopify’s ecosystem. When generating the service, we utilize as much of Shopify’s service infrastructure to deploy Merlin Services as any other Shopify service. This ensures that Merlin Services can scale to Shopify’s capabilities, as well as allowing them to integrate and benefit from the existing tooling that we have in place.
When a Merlin Service is created, it is registered to Shopify’s Services DB. Services DB is an internal tool used to track all production services running at Shopify. It supports creating new services and provides comprehensive views and tools to help development teams maintain and operate their services with high quality.

Once the Merlin Service is created, the entire build and deployment workflow is automatically generated for it. When a user merges new changes to their repository, Shopify’s Buildkite pipeline is automatically triggered and among other actions, builds the image for the service. In the next step of the workflow, that image is then deployed on Shopify’s Kubernetes clusters using our internal Shipit pipelines.
Merlin Service Configuration
Each Merlin Service is created with two configuration files, one for a production environment and one for a staging environment. These include settings for the resources, parameters and related artifacts of the service. Having a different configuration for each environment allows the user to define a different set of resources and parameters per environment. This can help optimize the resources used by the service, which in turn can reduce infrastructure cost. In addition, our users can leverage the staging environment of Merlin Services to test new model versions or configuration settings before deploying them to production.
The following is an example of a Merlin Service configuration file which contains different parameters such as the project name, metadata, artifact paths, CPU, memory, GPUs, autoscaling configuration, etc.:
This example shows a configuration file for the classification_model_example project which uses MLServer to serve its model. It uses at least 3 replicas that can scale to 10 replicas, and each one has 2 CPUs, 32 GB of memory and nvidia-tesla-t4 GPU. In addition, when the service starts, it will load a model from our model registry.
What’s Next for Merlin Online Inference
And there you have it, our path for deploying and serving machine learning models for real-time predictions with Merlin. To sum it up, our users start by creating a Merlin Project that contains everything required for their machine learning use case. An image is automatically built for their project which is then used in the training pipeline, resulting in a trained model that is saved to our model registry. If the use case requires online inference, Merlin can be used to create a serving layer and a dedicated Merlin Service. Once the service is deployed to production, Merlin users can continue iterating on their models and deploy new versions as they become available.

As we onboard new online inference use cases to Merlin we plan to tackle additional areas in order to enable:
- Ensemble models / inference graphs: while we have the ability to deploy and serve machine learning models, we are aware that in some cases we will need to combine multiple models in the inference process. We are looking into leveraging some open source tools that can help us achieve that with Ray Serve, Seldon Core or BentoML.
- Monitoring for online inference: with our current abilities, it is possible to create workflows, metrics and dashboards to detect different drifts. However, at the moment this step is completely manual and requires a lot of effort from our users. We want to enable a platform-based monitoring solution that will seamlessly integrate with the rest of Merlin.
- Continuous training: as the amount of input and data which are used for predictions increases, some of our use cases will need to start training their models more frequently and will require an automated and easier deployment process. We are looking into automating more of the service management process and lifecycle of our online inference models.
While online inference is still a new part of Merlin, it’s already empowering our users and data science teams with the low latency, scalability and fast iterations that we had in mind when designing it. We're excited to keep building the platform and onboarding new use cases, so we can continue to unlock new possibilities to keep merchants on the cutting edge of innovation. With Merlin we help enable the millions of businesses powered by Shopify.
Isaac Vidas is a tech lead on the ML Platform team, focusing on designing and building Merlin, Shopify’s machine learning platform. Connect with Isaac on LinkedIn.
Are you passionate about solving data problems and eager to learn more about Shopify? Check out openings on our careers page.