


On November 25, 2020 we held ShipIt! Presents: The State of Ruby Static Typing at Shopify. The video of the event is now available.
Shopify changes a lot. We merge around 400 commits to the main branch daily and deploy a new version or our monolith 40 times a day. Shopify is also big: 37,000 Ruby files, 622,000 methods, more than 2,000,000 calls. At this scale, with a dynamic language, even with the most rigorous review process and over 150 000 tests, it’s a challenge to ensure that everything runs smoothly. Developers benefit from a short feedback loop to ensure the stability of our monolith for our merchants.
In my first post, I talked about how we brought static typing to our core monolith. We adopted Sorbet in 2019, and the Ruby Infrastructure team continues to work on ways to make the development process safer, faster, and more enjoyable for Ruby developers. Currently, Sorbet is only enforced on our main monolith, but we have 60 internal projects using Sorbet as well. On our main monolith, we require all files to be at least typed: false and Sorbet is run on our continuous integration (CI) platform for every pull request and fails builds if type checking errors are found. As of today, 80% of our files (including tests) are typed: true or higher. Almost half of our calls are typed and half of our methods have signatures.
In this second post, I’ll present how we got from no Sorbet in our monolith to almost full coverage in the span of a few months. I’ll explain the challenges we faced, the tools we built to solve them, and the preliminary results of our experiment to reduce production errors with static typing.
Our Open-Source Tooling for Sorbet Adoption
Currently, Sorbet can’t understand all the constructs available in Ruby. Furthermore, Shopify relies on a lot of gems and frameworks, including Rails, that bring their own set of idioms. Increasing type coverage in our monolith meant finding ways to make Sorbet understand all of this. These are the tools we created to make it possible. They are open sourced in our effort to share our work with the community and make typing adoption easier for everyone.
Making Code Sorbet-compatible with RuboCop Sorbet
Even with gradual typing, moving our monolith to Sorbet required a lot of changes to remove or replace Ruby constructs that Sorbet couldn’t understand, such as non-constant superclasses or accessing constants through meta-programming with const_get. For this, we created RuboCop Sorbet, a suite of RuboCop rules allowing us to:
- forbid some of the constructs not recognized by Sorbet yet
- automatically correct those constructs to something Sorbet can understand.
We also use these cops to require a minimal typed level on all files of our monolith (at least typed: false for now, but soon typed: true) and enforce some styling conventions around the way we write signatures.
Creating RBI Files for Gems with Tapioca
One considerable piece missing when we started using Sorbet was Ruby Interface file (RBI) generation for gems. For Sorbet to understand code from required gems, we had two options:
- pass the full code of the gems to Sorbet which would make it slower and require making all gems compatible with Sorbet too
- pass a light representation of the gem content through an Ruby Interface file called a RBI file.
Being before the birth of Sorbet’s srb tool, we created our own: Tapioca. Tapioca provides an automated way to generate the appropriate RBI file for a given gem with high accuracy. It generates the definitions for all statically defined types and most of the runtime defined ones exported from a Ruby gem. It loads all the gems declared in the dependency list from the Gemfile into memory, then performs runtime introspection on the loaded types to understand their structure, and finally generates a complete RBI file for each gem with a versioned filename.
Tapioca is the de facto RBI generation tool at Shopify and used by a few renowned projects including Homebrew.
Creating RBI Files for Domain Specific Languages
Understanding the content of the gems wasn’t enough to allow type checking our monolith. At Shopify we use a lot of internal Domain Specific Languages (DSLs), most of them coming directly from Rails and often based on meta-programming. For example, the Active Record association belongs_to ends up defining tens of methods at runtime, none of which are statically visible to Sorbet. To enhance Sorbet coverage on our codebase we needed it to “see” those methods.
To solve this problem, we added RBI generation for Rails DSLs directly into Tapioca. Again, using runtime introspection, Tapioca analyzes the code of our application to generate RBI files containing a static definition for all the runtime-generated methods from Rails and other libraries.
Today Tapioca provides RBI generation for a lot of DSLs we use at Shopify:
- Active Record associations
- Active Record columns
- Active Record enums
- Active Record scopes
- Active Record typed store
- Action Mailer
- Active Resource
- Action Controller helpers
- Active Support current attributes
- Rails URL helpers
- FrozenRecord
- IdentityCache
- Google Protobuf definitions
- SmartProperties
- StateMachines
- …and the list is growing everyday
Building Tooling on Top of Sorbet with Spoom
As we began using Sorbet, the need for tooling built on top of it was more and more apparent. For example, Tapioca itself depends on Sorbet to list the symbols for which we need to generate RBI definitions.
Sorbet is a really fast Ruby parser that can build an Abstract Syntax Tree (AST) of our monolith in a matter of seconds versus a few minutes for the Whitequark parser. We believe that in the future a lot of tools such as linters, cops, or static analyzers can benefit from this speed.
Sorbet also provides a Language Server Protocol (LSP) with the option --lsp. Using this option, Sorbet can act as a server that is interrogated by other tools programmatically. LSP scales much better than using the file output by Sorbet with the --print option (see for example parse-tree-json or symbol-table-json) that spits out GBs of JSON for our monolith. Using LSP, we get answers in a few milliseconds instead of parsing those gigantic JSON files. This is generally how the language plugins for IDEs are implemented.
To facilitate the development of external tools to Sorbet we created Spoom, our toolbox to use Sorbet programmatically. It provides a set of useful features to interact with Sorbet, parse the configuration files, list the type checked files, collect metrics, or automatically bump files to higher strictnesses and comes with a Ruby API to connect with Sorbet’s LSP mode.
Today, Spoom is at the heart of our typing coverage reporting and provides the beautiful visualizations used in our SorbetMetrics dashboard.
Sharing Lessons Learned
After more than a year using Sorbet on our codebases, we learned a lot. I’ll share some insights about what typing did for us, which benefits it brings, and some of the limitations it implies.
Build, Measure, Learn
There’s a very scientific way to approach building products, encapsulated in the Build-Measure-Learn loop pioneered by Eric Ries. Our team believes in intuition, but we still prefer empirical proofs when we have access to them. So when we started with static typing in Ruby, we all believed it would be useful for our developers, but wanted to measure its effects and have hard data. This allows us to decide what we should concentrate on next based on the outcome of our measurements.
I talked about observing metrics, surveying developer happiness, or getting feedback through interviews in part 1, but my team wanted to go further and correlate the impact of typing on production errors. So, we conducted a series of controlled experiments to validate our assumptions.
Since our monolith evolves very fast, it becomes hard to observe the direct impact of typing on production. New features are added every day which gives rise to new errors while we work to decrease errors in other areas. Moreover, our monolith has about 500 gem dependencies (including transitive dependencies), any of which could introduce new errors in a version bump.
For this reason, we decreased our scope and targeted a smaller codebase for our experiment. Our internal developer tool, aptly named dev, was an ideal candidate. It’s a mature codebase that changes slowly and by a few people. It’s a very opinionated codebase with no external dependencies (the few dependencies it has are vendored), so it could satisfy the performance requirements of a command-line tool. Additionally, dev almost uses no meta-programming, especially not the kind normally coming from external libraries. Finally, it’s a tool with heavy usage since it’s the main development tool used by all developers at Shopify for their day-to-day work. It runs thousands of times a day on hundreds of different computers, there’s no edge case—at this scale, if something can break, it will.
We started monitoring all errors raised by dev in production, categorized the errors, analyzed their root cause, and tried to understand how typing could avoid them.
typed: ignore means typed: debt
Our first realisation was to keep away from typed: ignore. Ignoring a file can cause errors to appear in other files because those other files may reference something defined in the ignored file.
For example, if we opt to ignore this file:
Sorbet will raise errors in this file:
Since Sorbet doesn't even parse the file a.rb, it won’t know where constant A was defined. The more files you ignore, the more this case arises, especially when ignoring library files. This makes it harder and harder for other developers to type their own code.
As a rule of thumb at Shopify, we aim to have all our application files at least at typed: true and our test files at least at typed: false. We reserve typed: ignore for some test files that are particularly hard to type (because of mocking, stubbing, and fixtures), or some very specific files such as Protobuf definition files (which we handle through DSLs RBI generation with Tapioca).
Benefits Realized, Even at typed: false
Even at typed: false, Sorbet provides safety in our codebase by checking that all the constants resolve. Thanks to this, we now avoid mistakes triggering NameErrors either in CI or production.
Enabling Sorbet on our monolith allowed us to find and fix a few mistakes such as:
-
StandardExceptioninstead ofStandardError -
NotImplementedinstead ofNotImplementedError
We found dead code referencing constants deleted months ago. Interestingly, while most of the main execution paths were covered by tests, code paths for error handling were the places where we found the most NameErrors.
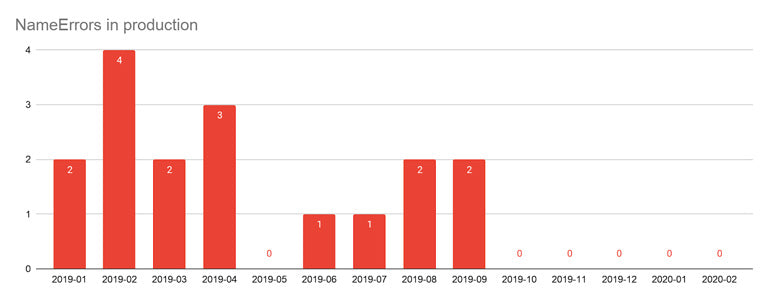
NameErrors raised in production for the dev project
During our experiment, we started by moving all files from dev to typed: false without adding any signatures. As soon as Sorbet was enabled in October 2019 on this project, no more NameErrors were raised in production.

NameError raised in production after Sorbet was enabled because of meta-programming
The same observation was made on multiple projects: enabling Sorbet on a codebase eradicates all NameErrors due to developers’ mistakes. Note that this doesn’t avoid NameErrors triggered through metaprogramming, for example, when using const_get.
While Sorbet is a bit more restrictive when it comes to resolve constants, this strictness can be beneficial for developers:
Example of constant resolution error raised by Sorbet
typed: true Brings More Benefits
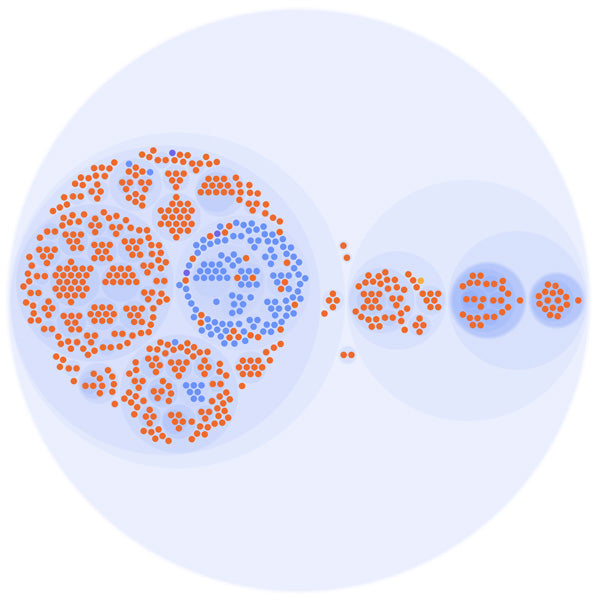
Files strictnesses in dev (the colored dots are the helpers)
With our next experiment on gradual typing, we wanted to observe the effects of moving parts of the dev application to typed: true. We moved a few of the typed: false files to typed: true by focusing on the most reused part of the application, called helpers (the blue dots).
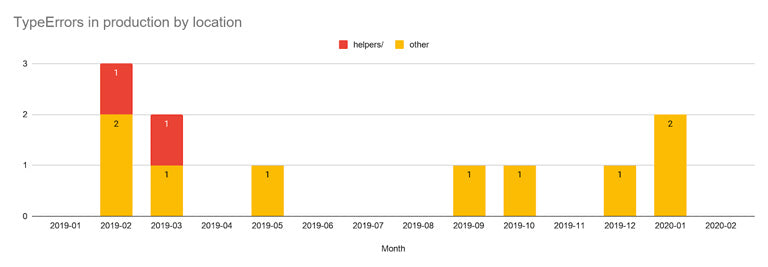
NoMethodErrors in production for dev (in red the errors raised from the helpers)
By typing only this part of the application (~20% of the files) and still without signatures, we observed a decrease in NoMethodErrors for files typed: true.
Those preliminary results gave us confidence that a stricter typing can impact other classes of errors. We’re now in the process of adding signatures to the typed: true files in dev so we can observe their effect on TypeErrors and ArgumentErrors in production.
The Road Ahead of Us
The team working on Sorbet adoption is part of the broader Ruby Infrastructure team which is responsible for delivering a fast, scalable, and safe Ruby language for Shopify. As part of that mandate, we believe there are more things we can do to increase Ruby performance when the types of variables are known ahead of time. This is an interesting area to explore for the team as our adoption of typing increases and we’re certainly thinking about investing in this in the near future.
Support for Ruby 2.7
We keep our monolith as close as possible to Ruby trunk. This means we moved to Ruby 2.7 months ago. Doing so required a lot of changes in Sorbet itself to support syntax changes such as beginless ranges and numbered parameters, as well as new behaviors like forbidding circular argument references. Some work is still in progress to support the new forwarding arguments syntax and pattern matching. Stripe is currently working on making the keyword arguments compatible with Ruby 2.7 behavior.
100% Files at typed: true
The next objective for our monolith is to move 100% of our files to at least typed: true and make it mandatory for all new files going forward. Doing so implies making both Sorbet and our tooling smarter to handle the last Ruby idioms and constructs we can’t type check yet.
We’re currently focusing on changing Sorbet to support Rails ActiveSupport::Concerns (Sorbet pull requests #3424, #3468, #3486) and providing a solution to inclusion requirements. As well as, improvement to Tapioca for better RBI generation for generics and GraphQL support.
Investing in the Future of Static Typing for Ruby
Sorbet isn’t the end of the road concerning Ruby type checking. Matz announced that Ruby 3 will ship with RBS, another approach to type check Ruby programs. While the solution isn’t yet mature enough for our needs (mainly because of speed and some other limitations explained by Stripe) we’re already collaborating with Ruby core developers, academics, and Stripe to make its specification better for everyone.
Notably, we have open-sourced RBS parser, a C++ parser for RBS capable of translating a subset of RBS to RBI, and are now working on making RBS partially compatible with Sorbet.
We believe that typing, whatever the solution used is greatly beneficial for Ruby, Shopify, and our merchants so we'll continue to invest heavily in it. We want to increase the typing for the whole community.
We’ll continue to work with collaborators to push typing in Ruby even further. As we lessen the effort needed to adopt Sorbet, specifically on Rails projects, we’ll start making gradual typing mandatory on more internal projects. We will help teams start adopting at typed: false and move to stricter typing gradually.
As our long term goal, we hope to bring Ruby on par with compiled and statically typed languages regarding safety, speed and tooling.
Do you want to be part of this effort? Feel free to contribute to Sorbet (there are a lot of good first issues to begin with), check our many open-source projects or take a look at how you can join our team.
Happy typing!
—The Ruby Infrastructure Team
We're planning to DOUBLE our engineering team in 2021 by hiring 2,021 new technical roles (see what we did there?). Our platform handled record-breaking sales over BFCM and commerce isn't slowing down. Help us scale & make commerce better for everyone.